
人-物交互检测(三):CDN
CDN的代码来自QPIC和DETR,然后衍生了GEN-ViKT,然后衍生成了Diffhoi。论文地址:[2108.05077] Mining the Benefits of Two-stage and One-stage HOI Detection (arxiv.org)。这里的实验分为CDN-S和CDN-L,意思是小规模和大规模,后续几篇论文也是这样的,先看这篇吧。
摘要
近些年来两阶段方法一直主导着HOI检测(当然这篇论文是2021年的,现在已经是transformer的时代了)。近期,一阶段HOI检测方法也变得流行起来。这篇论文里,作者旨在挖掘两种方法的优缺点。作者发现,传统两阶段方法主要在定位正面(positive)交互对样本时有问题,一阶段在多任务学习时不好做出权衡,也就是目标检测和动作分类。因此,一个关键问题就是,如何从两种传统方法中扬长避短。为此,作者提出了一个新的单阶段框架,以级联的方式解开人物检测和交互分类。具体来说,作者首先基于先进的检测器,把它们的交互分类部分移除,以此设计了一个人/物对生成器。然后作者设计了一个相对独立的交互分类器来分类每个人/物对。这个架构里的两个级联的解码器关注于具体的任务。具体实现,作者采用一个基于transformer的HOI检测器作为基本模型。代码: YueLiao/CDN: Code for "Mining the Benefits of Two-stage and One-stage HOI Detection" (github.com)
简介
先是说了啥是HOI,然后说现在有两阶段和一阶段的方法来完成这个任务,作者要挖掘二者的好处。先贴个图:
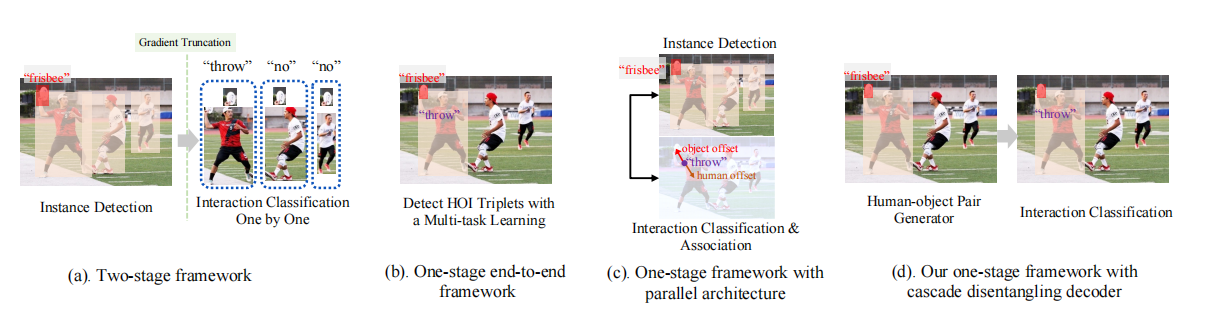
作者首先谈及传统的HOI检测器。两阶段方法通常是一个序列模型,如上图a。两阶段模型先检测人和物,然后用后续网络或手段一一检测每个人物对。这种方法只基于局部特征,会有大量负样本,因此会带来问题。而且,性能也会受到序列架构限制。为了解决这些问题,单阶段模型就被提出来直接预测HOI三元组,把HOI检测分开为多任务学习,也就是目标检测和交互分类,如上图b。因此,一阶段模型可以聚焦在交互人物对上,高效提取相应特征。然而,单个模型在多任务学习上很难权衡,因为模型要聚焦于不同的视觉特征。如上图c,尽管有些模型会设计两个平行的分支来检测示例和预测交互,交互分类的分支仍然需要回归额外的offsets来关联人物。也就是说,交互分支仍然需要在交互分类和人物定位之间作权衡。
因此,一个直接的想法就是从两种范式框架里扬长避短。作者就提出了一个一阶段的端到端框架,以级联的方式解开了人物(是人和物,不是person的人物)预测和交互分类,称作CDN,cascade disentangling network。初始想法是保有一阶段模型的优点,直接准确定位交互人物对,并且结合两阶段模型优点,解开人物检测和交互分类。如上图d,这个框架中作者基于一阶段范式设计了一个人物对decoder,移除了交互分类功能,这个解码器叫做HO-PD,之后接上一个单独的交互分类器。为了实现这个想法,作者就用之前的先进一阶段框架,HOTR和QPIC,对每个query而言移除了交互分类头,使得它们更专注于人物对的检测。此外,作者又设计了一个独立的HOI解码器来预测分类,使它不受人物检测的干扰。这样一来,又有一个关键问题:也就是如何把这两个人物对和对应动作类别链接起来。为了解决这问题,作者用HO-PD最后一层输出来初始化HOI解码器的query embedding。这样一来,HOI解码器就能在query embedding的指导下学习对应动作类别,并且不受人物检测影响。此外,作者还设计了一个解耦动态重加权方法(decoupling dynamic re-weighting manner)来处理数据长尾问题。
两阶段和一阶段HOI检测器分析
也还是那些东西,就不细说了。
两阶段HOI检测器
这一段就是说先预测M个人框,N个物框(这个物是包括人类类别的通用目标);这M*N个人物对里有K个true-positive样本,远远小于M*N,这样带来三个问题:1.需要额外的计算复杂度,2.正负样本数量不均衡会让模型对负样本过拟合,因此模型需要给"no-interaction"这个类别分配很高的置信度,抑制对true-positive样本的检测,3.交互分类的精度受到非端到端pipeline的影响。因为交互分类主要依赖于区域特征,而前面检测器的核心又是回归bbox,更多的是聚焦于局部区域的边界,因此不是很好的用于交互分类的特征,需要更多上下文。但是,两阶段的好处是,目标检测和分类可以让各个stage专注于产出更好的结果。
一阶段HOI检测器
单阶段很大程度上缓解了上述三个问题,尤其复杂度降低了很多。大多数一阶段方法是交互驱动的,直接定位交互点或者交互人物对,因此介绍了负样本的干扰。但是把人物检测和交互分类耦合在一起会限制性能,因为很难为两种很不一样的任务生成一个统一特征表示。尽管有些方法把HOI检测分为两个parallel branches,他们的交互分支依旧受到多任务学习影响。
方法论
先给出框架图。猪一样有个经过Qd的虚线Xs,那个虚线跟Qd没关系,第一次看还有点没看懂那条虚线咋经过queries了。
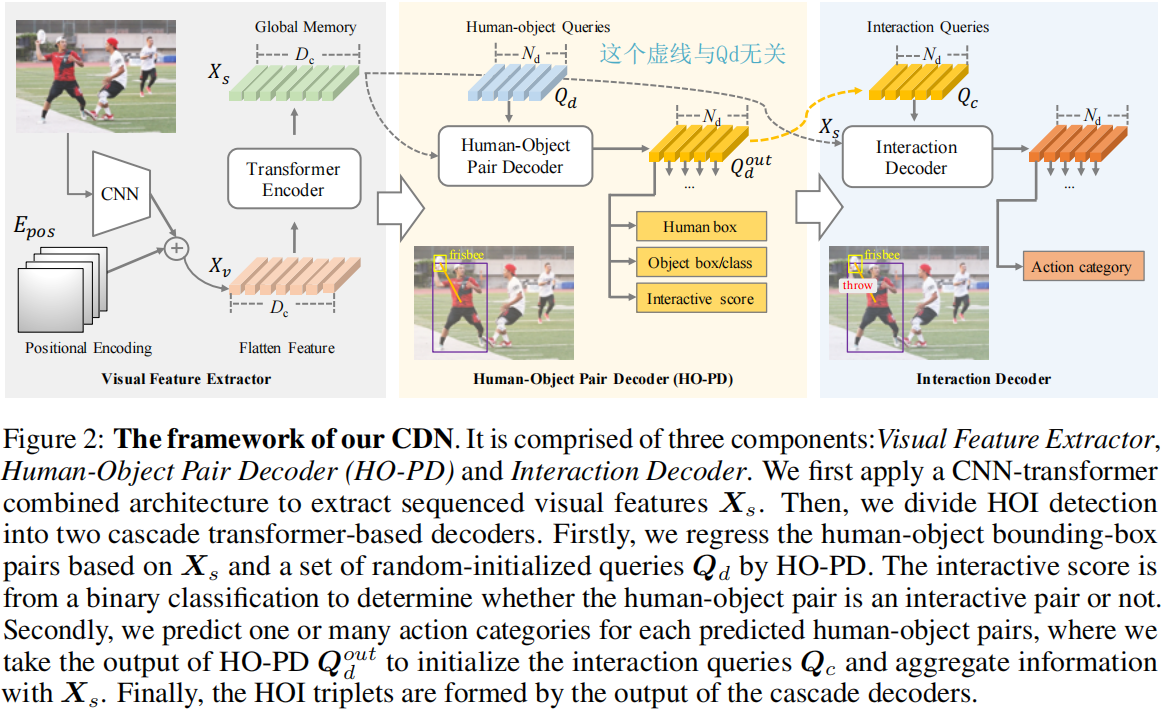
总览
给定一个图像x,先依据基于transformer的检测方法,把视觉特征提取成一个序列。然后用级联解码器检测HOI三元组,首先用Human-Object Pair Decoder,叫做HO-PD,基于一组可学习的queries预测一个人物框对集合;然后把HO-PD最后一层输出拿出来作为queries,用一个独立的交互解码器为每个query预测动作类别。
视觉特征提取器
跟DETR这些差不多,就是用了个CNN和TF编码器,加个位置编码。解码器输出被定义为一个
级联的分解开的HOI解码器(Cascade Disentangling HOI Decoder)
由两部分组成,HOPD和交互解码器。两个解码器架构相同,权重独立。
基于TF的解码器
作者遵循DETR的基于tf的目标检测器来设计基本架构。作者应用N个tf解码器层,每个解码器层配备若干FFN头部以intermediate
supervision(中继监督优化)。具体来说,每个解码器层包括一个自注意力模块和一个多头协同注意力模块。前向传播时,每个解码器层输入一组可学习的queries,先对所有queries用自注意力机制,然后在queries和序列化视觉特征间作协同注意力操作,输出一组更新的queries。对于FFN头部,每个都包括一或多个MLP分支,每个分支针对各自具体工作,比如分类和回归。所有queries共享相同的FFN头部。每个解码器可以被描述为:
HO-PD
首先,作者设计HO-PD来从序列化视觉特征里预测一组人物对。为此,作者首先随机初始化一组可学习的queries
,
Intreaction Decoder
然后,作者用交互解码器分类人-物
queries,分配一或多个动作。为此,作者用HO-PD的输出
Decoupling Dynamic Re-weighting
HOI数据集通常对物体类别和动作类别都有长尾分布。为此,作者以一种解耦合的训练策略,设计了动态重加权机制来改善性能。具体来说,作者先用常规loss训练整个模型。之后,作者冻结视觉特征提取器的参数,然后用相对小的学习率和设计好的动态重加权损失来只训练级联的解码器。
在解耦合训练的每个迭代中,作者用两个相似的队列来累积每个物体类别或交互类别的数量。这些队列被用作memory
banks,来累积训练样本,并以长度
训练和后处理
本小节介绍训练和推理的细节,并且推理时介绍作者提出的新方法PNMS,Pair-wise Non-Maximal Suppresion。
训练
依据HOTR和QPIC,首先用匈牙利算法二分类匹配,为每个真实值匹配出它最佳的预测。然后匹配的预测和相应真实值之间的损失被计算出来用于反向传播。匹配时,作者将两个级联解码器的预测一起考虑。CDN的loss遵从QPIC,包括五部分:框回归损失
推理
推理过程是把实例相关FFNs输出和交互相关FFN的输出结合成HOI三元组。由于级联解码器使得instance
queries和interaction
queries是一一对应的,因此五元组<hb,ob,ocls,交互得分,alcs>在每个
the instance queries and the interaction queries are one-to-one corresponding, therefore, the five
components <human bounding box, object bounding box, object class, interactive score, action class>
can be homologous in each of the
PNMS
在排序出
实验
数据集是HICO和VCOCO。模型有三种变体:CDN-S/B/L。CDN-S、CDN-B是用resnet50和六层tf编码器作为视觉特征提取器;前者解码器三层,后者解码器六层。CDN-L把resnet50换成了resnet101,其他与CDN-B一样。Dc设置为256,Nd对HICO设置为64,对VCOCO设置为100.

