
论文阅读:基于梯度优化的面向高效客户端选择的生成式框架
摘要
考虑问题:异构性、高能耗。因此,需要高效的客户端选择策略。传统方法的启发式方法和基于学习的方法,无法全面解决这些复杂问题。因此本文提出FedGCS,一种创新的生成式客户端选择框架,首次将客户端选择过程重新定义为一个生成任务(其实在最早说的那篇ASP选择任务里也是生成任务,只不过嵌入到了强化学习框架里;本文认为强化学习有效但没有考虑模型性能、延迟等方面)。FedGCS 受大语言模型方法的启发,通过构建连续表示空间,有效地编码了丰富的决策知识,并利用基于梯度的优化方法搜索最优的客户端选择方案,最终通过生成输出最佳结果。
该框架包括以下四个步骤:1.自动化数据收集:利用经典的客户端选择方法自动收集多样化的“选择-评分”数据对;2.训练编码器-评估器-解码器框架:基于上述数据构建连续表示空间;3.基于梯度的优化:在连续表示空间中优化以找到最佳的客户端选择;4.生成最优客户端选择:通过对训练良好的解码器使用束搜索(beam search)生成最终选择结果。
简介
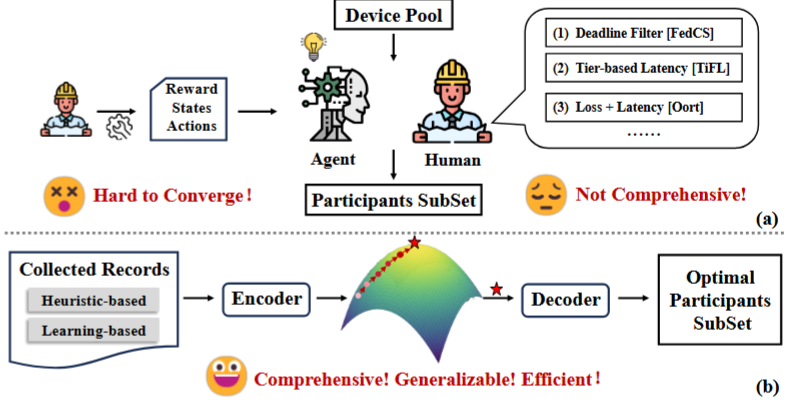
↑↑↑强化学习不好收敛,启发式算法不全面 本文模型三个感叹号
问题建模
主要是将离散客户端选择任务表述为生成任务,并在连续表示空间中进行基于梯度的优化以获得最优选择。首先在训练轮次开始时,在包含J个设备的设备池中,使用经典客户端选择算法收集
n
对“选择-评分(记作(s,p)”数据作为后续模型训练的训练数据。收集到的记录集合记为
R。对于p, 是客户端选择
本文评分考虑:1.全局模型的良好性能;2.较低的处理延迟;3.较低的能耗。因此本文的评价函数定义为:
为了能有梯度,需要把这些离散数据表示到连续空间。具体来说需要学习三个模块:1.一个编码器
方法
框架的全图见下:
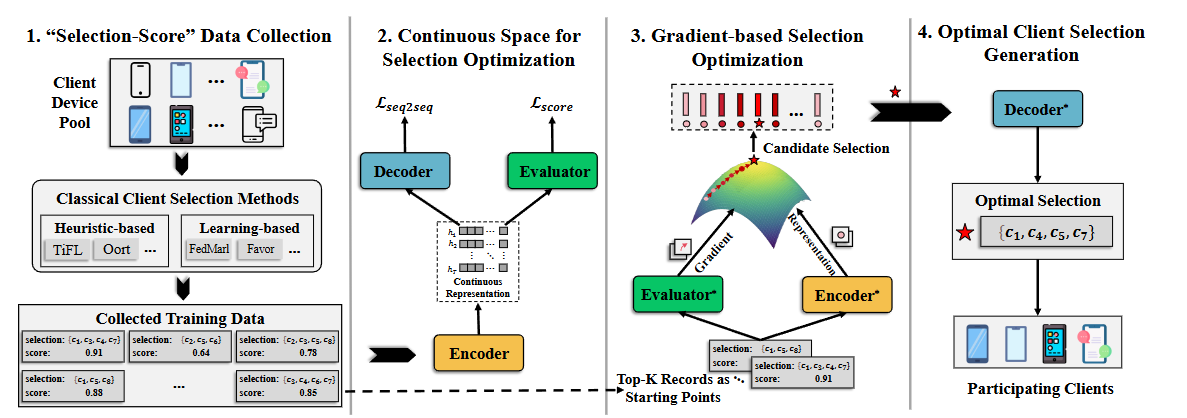
选择-评分数据收集
用先前的启发式算法或强化学习方法完成。记作
连续空间
在获得R后,需要把它映射到连续表征空间以可以梯度下降。
数据增强
由于输入输出都是客户端选择集合,因此此处相关模型是seq2seq的模型。由于是集合,为了建模出这种跟顺序无关的特点,作者使用一种数据增强的手段:其实就是随机shuffle一个选择中的设备ID,以获得一个新的order。
编码器
需要得到连续特征表示
解码器
即用
为了让生成的序列和真实的序列相似自然要设计损失函数。为此,在这一步最大化分布P的对数似然,即
评估器
给定一个选择s序列,需要基于
整体损失就是这两个
基于梯度的选择优化
通过上面的过程,可以得到训练后的编码-解码器和评估器。之后,就可以用梯度下降的方法去寻找最优的客户端选择。为了合理正确的初始化模型,先选择最高的K个<s,p>对并编码成连续空间里的表示。
假设其中一个编码结果是
