
论文阅读-多接入AIoT中面向GAI服务的基于动态量化的安全联邦扩散模型
这篇论文主要考虑了联邦扩散模型下的隐私保护和通信开销,并于另一篇FedDiff做实验对比:FedDiff: Diffusion Model Driven Federated Learning for Multi-Modal and Multi-Clients | IEEE Journals & Magazine | IEEE Xplore;2024.5. 这些联邦扩散模型论文基本都是2024左右开始的。不过这些论文做实验直接拿多块GPU当下面的client的,看看思路就行了^
摘要
AIGC的应用标志着从IoT向人工智能物联网(AIoT)演进的重要进步。考虑到AIoT的多接入特性,通过联邦学习训练GDMs并协同部署显得尤为重要。然而,这种方法带来了显著的安全风险和能耗挑战。为解决这些问题,作者提出了一种涵盖训练和采样阶段的GDMs综合架构,称为SS-Diff。该架构旨在防御基于触发器的安全威胁(如后门攻击和木马攻击),同时降低多接入AIoT中的能耗。SS-Diff架构在训练阶段引入了动态量化机制,显著减少了通信开销,从而提升了频谱效率和能源效率。在采样阶段,采用基于检测的防御策略,识别并抵消与恶意攻击相关的触发输入。
就是说训练阶段减少开销,采样阶段搞安全防护,结果表明与现有方案相比,SS-Diff能够有效训练GDMs并消除攻击影响。
简介
为应对高质量内容的需求,GDMs被应用于多接入AIoT环境中,利用AI服务提供商的通用GDM,各设备可微调适配其领域的专用GDM。
为解决隐私问题,FedDiff被提出,使设备能够在无需共享数据的情况下利用本地数据微调GDM。此外,为应对计算资源和延迟挑战,这个方法提出了协作采样方法,以提高扩散模型的性能。
尽管隐私和计算成本问题得到部分解决,多接入环境下GDM的应用仍面临显著挑战:1.安全问题:恶意或受攻击设备可能在训练或采样阶段注入后门,生成特定有害内容。2.通信能耗:GDM的联邦学习训练需要频繁在边缘节点与设备之间传输模型,导致高能耗。
针对此,本文就引入了动态量化来进一步减少能耗;同时提出了有效的攻击检测方法来提高安全性。
系统模型
GDM AIoT架构
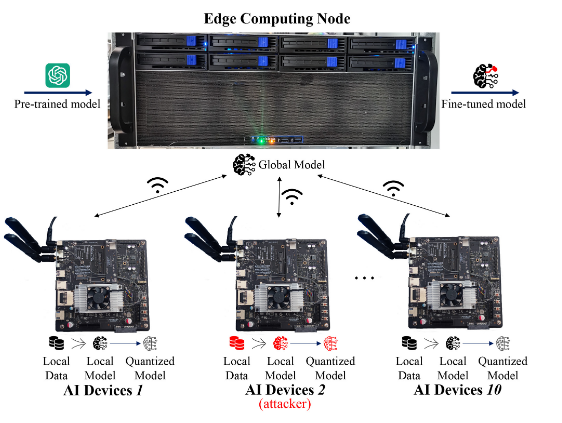
如下图,涉及三个角色。1.AI服务提供商,就是提供预训练模型的。2.AI设备,位于终端,具备一定计算、存储、通信能力,比如智能汽车智能手机。3.边缘计算节点,靠近数据收集、生成的位置。
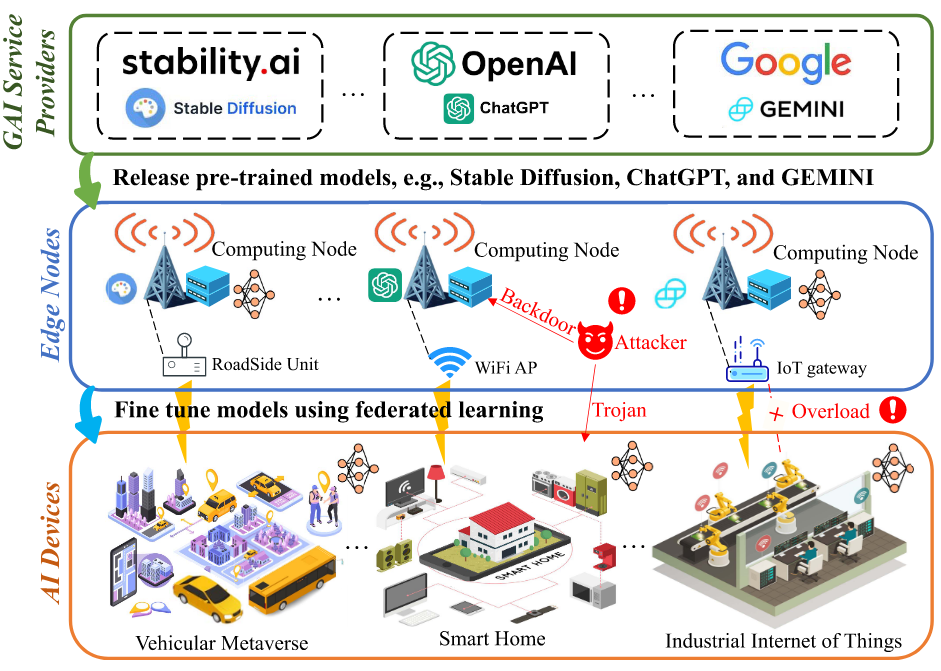
来自不同部门的AI设备对内容生成的需求各不相同,且设备之间也要有数据隐私标准。联邦学习过程如下:1.边缘计算节点将该预训练模型分发至AI设备。2.AI设备利用本地数据进行多次迭代训练,并将本地模型上传。3.边缘计算节点将这些本地模型进行聚合,生成更新的全局模型,并发送回AI设备以进行进一步训练。4.这一过程反复进行,直至模型收敛,得到最终的全局模型。
GDM与传统AI模型的关键区别在于采样阶段。不同于判别模型中推理阶段的一次性完成,GDM的采样阶段需要重复多次。因此,与训练相比,采样阶段的计算开销更大。协作扩散提供了一种高效的解决方案:采样过程被划分为共享阶段和本地阶段。共享采样:使用相同模型的设备将初始输入发送至边缘计算节点,节点执行若干共享采样步骤。本地采样:边缘计算节点将中间结果返回设备,设备完成剩余的本地采样步骤。
威胁模型
假设最多有三成设备会被攻击,边缘节点不会被攻击;攻击者会向模型注入恶意生成内容或者插件。
SS-Diff框架
SS-Diff包括一个训练阶段,该阶段通过量化压缩和最优资源调度来最小化能耗,然后上传本地模型。同时,它还包含一个采样阶段,引入创新的检测技术来过滤带有触发器的输入,从而确保整个多接入AIoT的安全性。
训练阶段
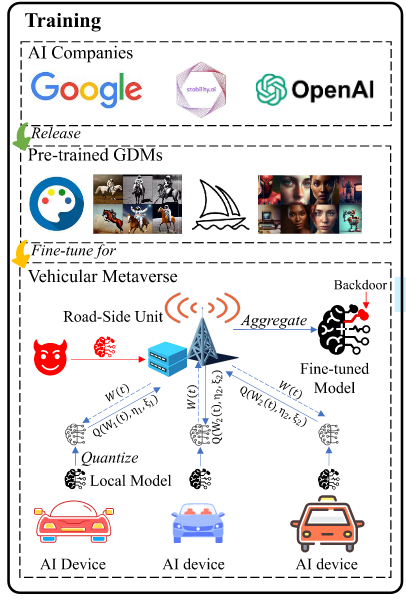
多接入AIoT中,AI设备具有有限的计算和通信资源,并且拥有独特的私有数据集。在训练阶段,边缘计算节点会随机选择一部分AI设备参与每轮训练。为了减少传输成本,在这一过程中应用了动态量化,在AI设备将本地模型上传到边缘计算节点进行聚合之前进行压缩。SS-Diff的训练过程如下:
1.AI服务提供商将预训练的模型发送给参与训练的AI设备和边缘计算节点。
2.每个AI设备根据当前的资源设置量化级别,并将该信息传输给边缘计算节点。
3.考虑到量化要求的差异,边缘计算节点为每个设备确定适当的策略,平衡计算和通信资源,以实现整体效率的最优。
4.AI设备并行地使用私有数据执行扩散迭代,创建新的本地扩散模型。
5.AI设备根据其量化级别对本地模型进行量化,并将这些量化后的模型上传至边缘计算节点。
6.边缘计算节点将所有本地扩散模型去量化后聚合成一个全局模型。
7.重复步骤2,直到收敛
在这里,量化后的权重表示为:
然后是计算、通信模型。f表示计算频率,D是本地数据集大小,则训练DM的计算时间为
本文用正交频分多址(OFDMA)传输方案来传输量化后的本地扩散模型。OFDMA
将可用带宽划分为多个正交资源块。通过利用OFDMA,可以在多接入AIoT场景中实现高数据率和鲁棒的通信。考虑将一组N个上行正交资源块分配给AI设备。AI设备j的资源块向量表示为
令传输功率为
采样过程
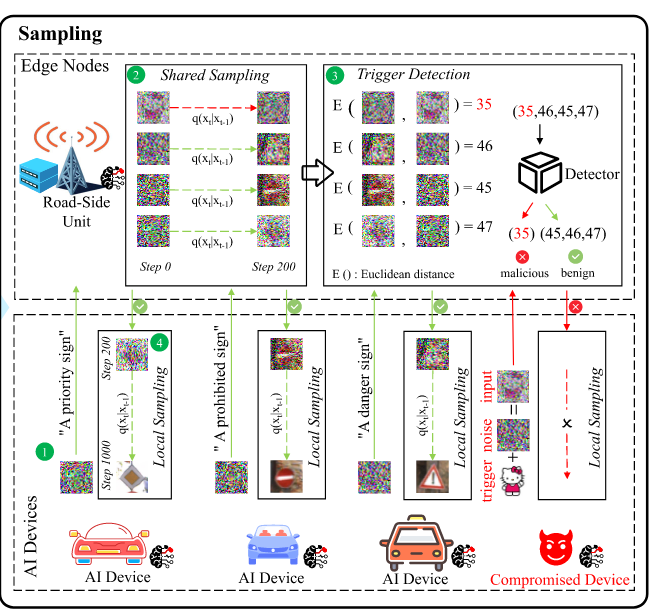
主要是说防攻击。文章说,backdoor攻击、木马攻击有一个共同特点:在采样过程中输入噪声带有触发器,这时受攻击的全局扩散模型(GDM)会生成有害内容。作者发现,在相同的采样步骤之后,正常输入和带触发器的输入之间存在显著差异。本文通过测量每个输入与其对应的中间结果之间的欧几里得距离来衡量这一差异,该度量在带触发器的输入和正常输入之间非常不同。
由于防御者对攻击方法或触发器缺乏了解,因此这是一个无监督的二分类问题,旨在将带触发器的输入与正常输入区分开来。作者使用了四种检测器:average、maxsplit、max-min和K-means来解决这个问题。当然,也有可能因为过滤掉了正常图像而降低QoS,所以作者还用了一些剪裁的方法就不细说了。
算法过程:1.AI设备将初始噪声上传至边缘计算节点。2.边缘计算节点将接收到的初始噪声组成一个批次,并对其进行t步采样。3.边缘计算节点测量每个输入与其对应的中间结果之间的欧几里得距离,并使用一定算法,通过检测器过滤掉带触发器的输入。4.正常输入的中间结果被发送回AI设备进行本地采样,同时对带触发器的输入应用ITC进行后续采样。
能量节约的优化
量化误差边界分析
每个本地用户根据其个体需求确定最优资源优化策略,指定最大可接受的量化误差。量化误差平方期望的边界为:
资源分配
由于SS-Diff训练过程中消耗大量的能量,优化目标是基于不同的硬件配置来优化训练过程。问题建模为:
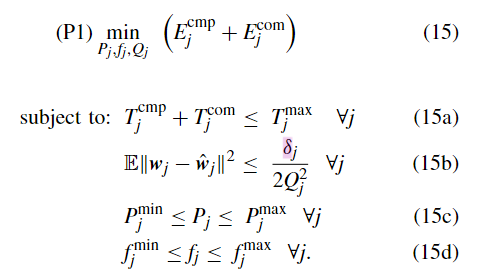
为了便于处理这个问题,引入两个变量:θ和π,使得:

然后变成拉格朗日函数形式,找KKT条件,然而进而可以找到最优解:
实验
实验是这么做的:模型现在CIFAR10数据集上预训练,然后用GTSRB这一交通标识数据集做微调。实验设备比较土豪:
实验结果比较了最终生成的质量(用一种叫FID的指标)、以及能量消耗,均优于FedDiff。
关于FedDIff即相关论文
FedDiff是一篇关于遥感的,是在做多模态遥感数据融合。示意图如下:
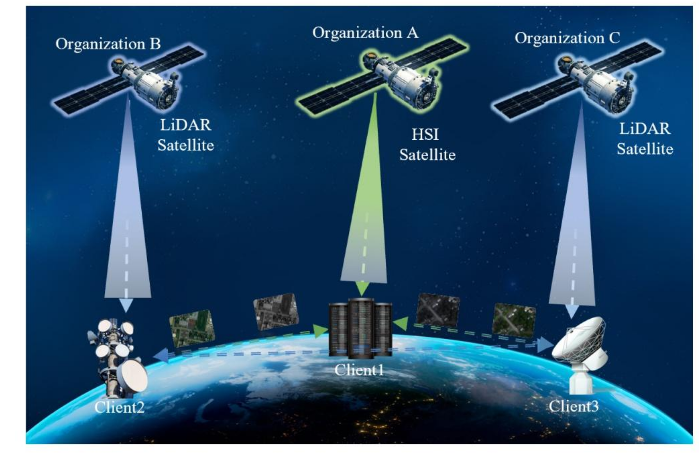
单一模式的卫星收集的数据是有局限性的;而不同种类卫星收集到的数据是不同模态的,因此需要融合多模态遥感数据,来做land cover土地覆盖分类任务。

这篇文章用的是分布式训练的框架,使用了联邦学习的思想;虽然说降低了通信成本,但是文章并未对通信建模(是通过对比实验中,数据大小来体现减小了通信开销的。)其框架为:包括HSI客户端和LiDAR客户端,客户端之间无需与原始数据交互,通过传输中间特征更新全局模型,实现多模态数据融合。
可以说,本文是针对具体任务,以多模态为背景做的工作(针对具体的异构数据的情况)。其网络结构如下:
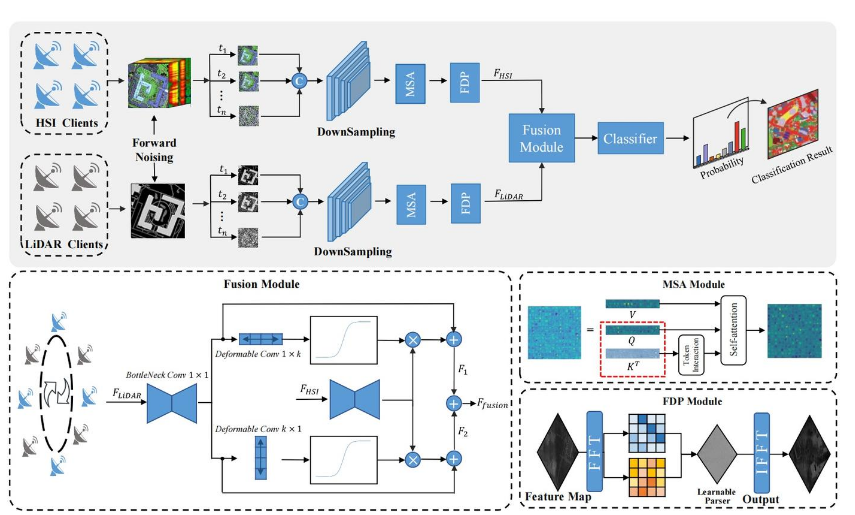
文章提出了一种多模态扩散模型,提出了一种扩散双分支框架,引入了多头注意力机制,并且利用FFT转换到频域来增强不同模态中的信息(用扩散模型是因为:对输入数据噪声体现出鲁棒性,因为遥感数据很容易收到噪声影响)。其实验是在一些遥感数据集和多模态数据集上完成的(HSI-LiDAR Houston2013、Trento multi-modal dataset等等)。
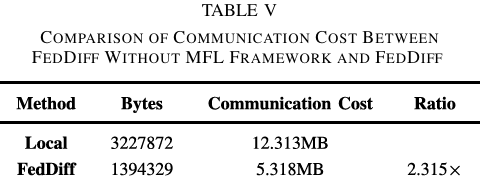
实验里,本文构建了一个多客户端基站系统,使用八个计算板模拟八个基站客户端,两种模态的在线数据以非独立且相同的分布式方式加载到每个客户端中。其通信成本是根据传输量度量的:
基于这种工作,也提出了FedDM、FedLEO、FedFusion等等处理多模态的分布式学习方法。
