论文阅读-SplitFed:联邦学习+分裂学习
地址:[2004.12088] SplitFed: When Federated Learning Meets Split Learning
摘要
联邦学习和分裂学习(FL和SL)是两种受欢迎的分布式机器学习方法。这两种都遵循一种model-to-data的场景;客户端无需要到raw data就可以训练、测试模型。SL还比FL提供了更好的模型隐私,因为模型会在服务器和客户端之间分隔开(就比如Conv1(S)->Conv2(C1)->Conv3(C2)...)。但是,比起FL,SL这种训练方式肯定更慢,因此本文提出一种新的方法叫splitfed(SFL),增强数据隐私和模型鲁棒性,在测试精度、通信效率上都表现良好。
简介
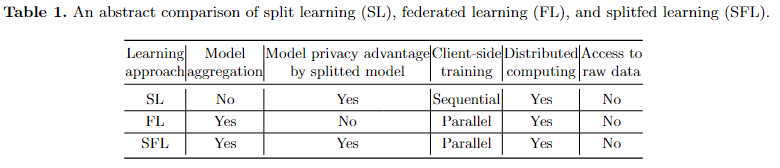
FL在分布式客户端上分别根据本地数据训练一个完整的模型,但是一些资源受限的客户端可能没法跑整个模型,且从模型隐私角度讲有隐患。为此,SL被提出:将完整的模型分成更小的一些网络部分并在服务器、客户端群上训练。这样,客户端减少了计算负载,且服务端、客户端无法互相访问模型。不过尽管如此,SL也有个问题:其中继式的训练使得同时只有一个客户端会与服务器交互,这样就增加了训练时间开销。(就是不并行的意思吧应该。)本文在四种数据集上用四种网络比较了SFL的通信效率、模型精度。
框架
这是它的框架图:
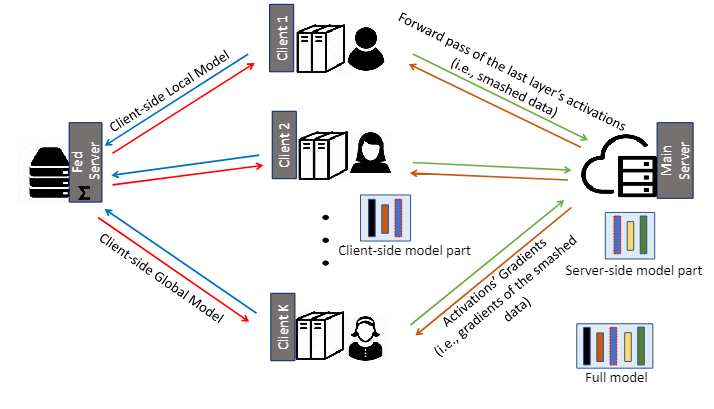
要说明的是,现有的方法都是以本地数据集为前提的,该方法也不例外。他把模型分为两部分,前部分在客户端上,后部分在server上。图里的顺序应该是:绿、棕、蓝、红。
工作流程
1.所有客户端在本地模型上并行执行前向传播,并将处理后(通常在激活函数处理后)的数据(称为stashed data)传送到主服务器。2.然后,主服务器在其服务器端模型上分别处理每个客户端的stashed data的前向传播和反向传播(在某种程度上是并行的)。3.接着,主服务器将这些处理后的数据的梯度发送给各个客户端进行反向传播。4.之后,服务器通过联邦平均(FedAvg)更新其模型,即通过对每个客户端的处理后数据在反向传播过程中计算的梯度进行加权平均。5.在客户端,收到其处理后数据的梯度后,每个客户端在本地模型上执行反向传播并计算梯度。
(本博客不主要考虑)一个差分隐私(DP)机制用于确保这些梯度的隐私性,并将其发送回联邦服务器。联邦服务器对客户端的本地更新执行FedAvg,并将结果返回给所有参与的客户端。
文章还提了一些变体,但其实也大差不差。比如说,不用聚合用一种串行的方式,增加精度;或者在有标签的情况下,为防止标签共享,把网络的最后几层也拿来在客户端上跑,
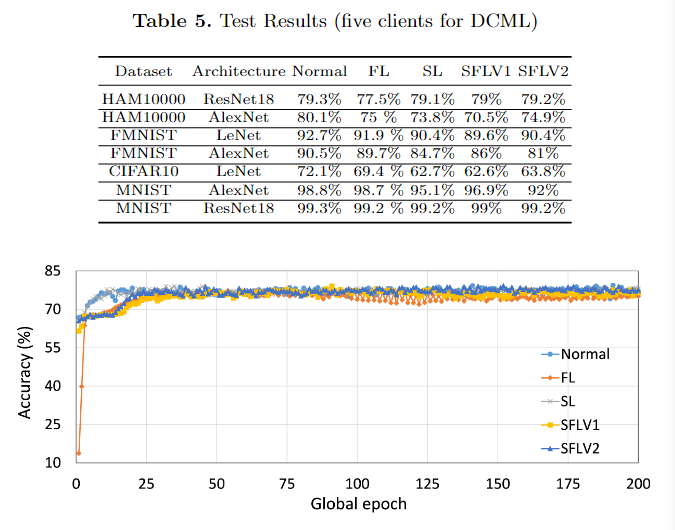
然后作者比较了精度,效果还是不错的。