
论文阅读-6G卫星高效联邦学习-基于DRL的多目标优化
摘要
基于无线的FL作为新兴的分布式学习方法,在6G系统中被广泛研究。当这一范式从地面网络转移到非地面网络,就会有更多挑战:例如LEO卫星服务时间有限、需要高效的上传和聚合时间。本文中,作者利用了LEO广泛的接入能力和FL的隐私保护和协作学习能力。与大多数FL工作不同,本文从多目标优化(MOO)的角度同时提高了通信训练效率和局部训练精度。为此,作者提出了一种基于分解、DRL和迁移学习的FL MOO算法DRT-FL,旨在动态适应星地环境,实现高效上传聚合,并逼近pareto最优集合(多目标优化问题上的帕累托最优)。
简介
以往基于无线通信的FL研究主要集中在覆盖范围有限的地面系统中,这些研究未能充分展示FL整合边缘设备碎片化计算资源的潜力。当6G范式从地面网络向非地面网络(NTN)转移时,低轨道卫星(LEO)成为6G NTN的重要组成部分。凭借广泛的覆盖范围和无缝连接能力,LEO可以作为FL中的中央服务器,用于聚合本地模型的参数并更新全局模型。
在LEO-FL系统中,现有研究仅在有限程度上探讨了相关问题,还有一些关键问题需要解决。首先,服务区域内只有部分设备可以参与FL本地训练,不同参与设备可能会影响全局模型的性能。因此,有效优化计算和通信资源尤为重要。其次,由于LEO的服务时间有限,需要在保持良好精度的同时减少整个FL过程中通信和计算所需的时间。
为了应对LEO-FL系统中的这些挑战,我们研究了一个LEO-FL系统,并通过联合确定设备选择、功率和计算资源分配,构建了一个多目标优化问题(MOP),以最小化全局模型收敛时间和通信-计算时间。据我们所知,这是首次尝试为LEO-FL系统研究高质量且高效的多目标优化(MOO)解决方案。
系统模型
LEO-FL系统
如图所示,我们考虑一种低地球轨道(LEO)卫星联邦学习(FL)系统,该系统包括一个装备了多天线的LEO卫星用于全局模型的共享和聚合,以及一组具有有限通信和计算资源的设备用于本地模型的更新和上传。我们将所有设备的集合记为
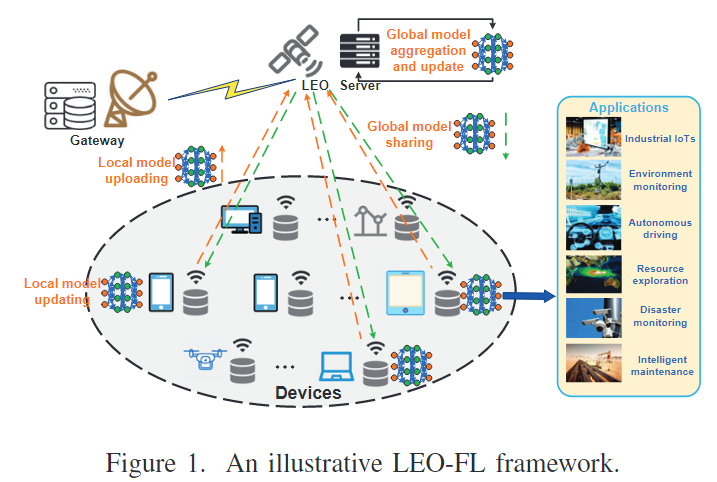
对于每个设备,它通过自身的本地数据集 D来更新其本地模型。该数据集包含 Dm个数据样本,每个样本x为特征,y为标签。考虑到LEO的动态位置和受限带宽,只有一部分设备参与FL训练。这些设备记为M'。
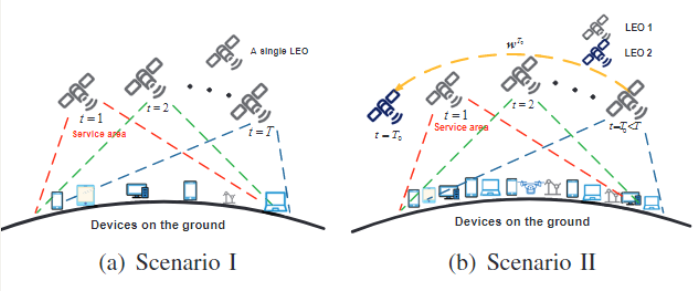
之后文章介绍了FL训练过程,包括T轮,就是寻常的FL过程,包括模型初始化、共享、更新上传、聚合等等。不作详细介绍了。本文考虑两种场景:一种是训练过程在单个LEO的服务时间内可以完成;一种是完成不了,当LEO离开服务区后全局模型就无法收敛或者准确率低。此时,下一个来的LEO需要重启FL训练过程。在这种模型中,作者考虑LEOs之间的协作,现有的全局模型可以由网关或者ISR传输。两种场景如图:
通信建模
上行通信
在上行通信中,本地模型从被选中的设备传输给LEO。假设利用设备位置、卫星轨道、速度等信息,可以在网关有效补偿高移动性LEO引起的多普勒频移。在第t轮,LEO与设备m间的信道状态h建模为:
下行通信
作者考虑了一种block fading
channel,h与上行一样。设备m的下行速率与通行时间定义为:
计算模型
在系统中,设备只有有限的计算能力更新本地模型。定义设备m处理一个样本需要的CPU
cycles数为c,样本集合D,
这里的g和上面的m都是从一个离散集合中取值,以代表一种等级分类。
通信-计算时间
在同步更新下,一轮的通信时间显然是要取max的,即:
此外,作者还采用了一种结合更新时间和训练损失的方法来衡量F(wt)(全局模型损失函数):$Ct = -$。这个式子作者就提了一嘴,不知道咋来的,感觉是为了硬凑多目标优化。
在本文系统模型中,作者旨在同时优化设备选择和资源分配,以同时实现全局模型训练收敛和减少通信-计算时间。为此,MOP问题建模为:
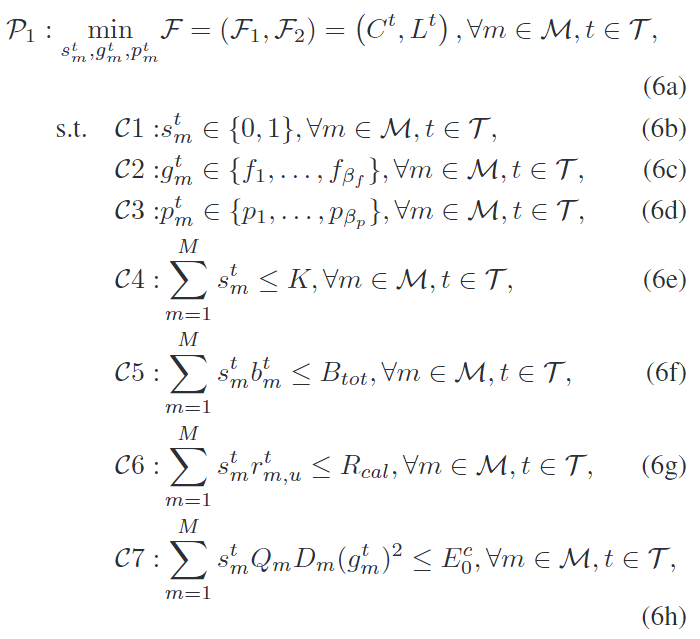
算法求解
帕累托的部分看不太懂,本博客主要讨论问题的场景,解决方案尽可能往上写吧。而且文章有问题,就给了一个问题P1,结果文章一直提到个P2,全文根本找不到。
DRT-FL核心想法
传统方法通过加权重方式把P1转化为SOP,但是由于C和L的维度会变化很大,影响权重设置。因此本文提出了一个新的基于分解、DRL和迁移学习的解法。
算法流程:1.首先,通过分解把MOP分解为几个单目标子问题。对每个子问题,其帕累托最优解
具体phase
phase 1:分解
使用一种常见的方法:加权和方法,这种方法基于权重向量
phase 2: DRL和迁移学习
分解之后,只需要同时优化这些子问题了。鉴于离散化带来的np-hard以及序列决策特征,作者把每个子问题转化为MDP并用DRL解决。
DRL的状态:
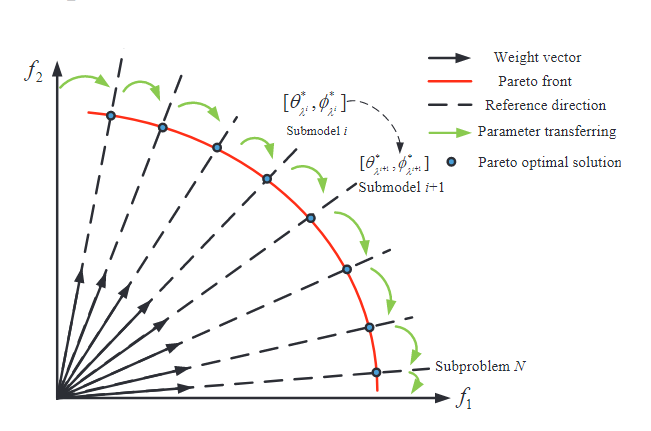
每个子问题的DRL训练都要大量episodes,非常耗时。为解决此,作者提出了一种迁移学习策略:一个权重向量对应的子问题,可以利用其邻近向量的知识迁移过来以加速训练。本文中,θ和φ是以序列的方式不断从一个子问题流到另一个子问题,如图:
实验
用了MLP和两种CNN做全局模型,数据集用MNIST和CIFAR-10。在训练阶段,数据样本随机分布给各设备,并采用了IID或者NON-IID的设置。但本文并没有对non-iid再做说明了。
本文主要探讨了未来6G卫星网络的场景,虽然提到了挑战包括异构设备但仅仅是提到了然后没然后了。
在这种背景下,可能考虑的:对于具体模型的异构处理?采用模型参数量化进一步减少开销?等等。
