
论文阅读-针对异构、长尾数据的CLIP引导的FL
[2312.08648] CLIP-guided Federated Learning on Heterogeneous and Long-Tailed Data,AAAI-24。
摘要
本文考虑的是图像分类任务。本文考虑的问题是:FL的挑战除了用户异质性,还有类别数目不均衡(也就是长尾问题,研究异质性多但是长尾的比较少)。由于CLIP在这种few/zero shot的任务上有成功的经验,于是作者就用CLIP来优化联邦学习。
具体来说,对于客户端的学习,是通过知识蒸馏使客户端模型与CLIP对齐,以提升客户端特征表示的能力。对于服务端,则根据客户端的梯度生成联邦特征来重训服务器模型。
简介
论文是在一个叫CReFF的工作基础上做的,引入了CLIP做语义监督。主要是考虑了两个问题和解法。1.如何利用CLIP提升客户端模型的特征表示能力?方法:CLIP当做教师,客户端当做教师,用知识蒸馏的思想传递知识来提高表示能力。2.如何利用CLIP缓解服务器模型的异质性和长尾问题?方法:在CLIP的语义监督下,通过客户端梯度生成联邦特征,使这些特征尽可能避免异质性和类别不均衡。然后,用这些特征重新训练平衡的服务器模型。
方法
问题建模
有一个中央服务器和K个客户端模型,客户端数据集为
在实验中,特征提取器用的ResNet-8;并添加了一层MLP以对齐CLIP输出特征的维度。
CLIP2FL框架
本文方法主要专注于本地模型训练和服务端模型聚合。
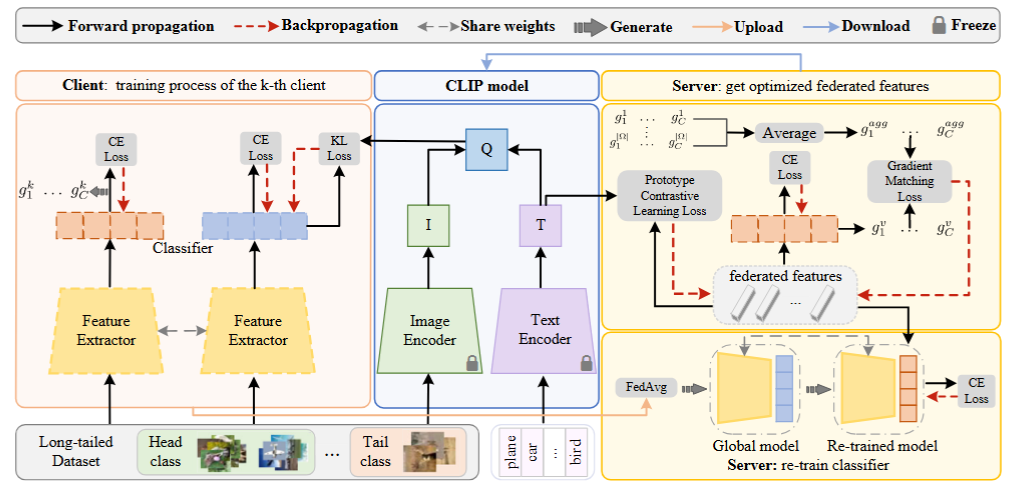
客户端学习
CLIP包括一个图像编码器和文本编码器。给定一个图像x和标签label,我们可以得到其视觉特征和文本特征。为了缓解异构性和长尾问题,客户端模型必须迫使其输出与CLIP输出一致。为此,本地训练损失函数为:
服务端学习
服务端学习要复杂一点。这一过程包括:聚合服务端分类器梯度、生成联邦特征、重训模型。
梯度聚合
作者要计算服务端分类器
联邦特征生成
首先,服务端对每一类别平均聚合真实梯度:
之后,在t轮里,对每个类别要生成一系列d维度的联邦特征
对于第一个约束,使用服务端分类头生成对应类别的联邦特征的梯度:
现在我们有:联邦特征
分类器重新训练
看了半天,这里的重训练指的是把全局模型拷贝一份,然后固定住特征提取器,用联邦特征去重新训练分类头参数,记作
联邦特征

实验
作者使用了三种常用的,存在长尾现象的数据集:CIFAR-10/100-LT和ImageNet-LT。对于前两个数据集,用一种不平衡因子采样,并在客户端之间形成异构的数据集。
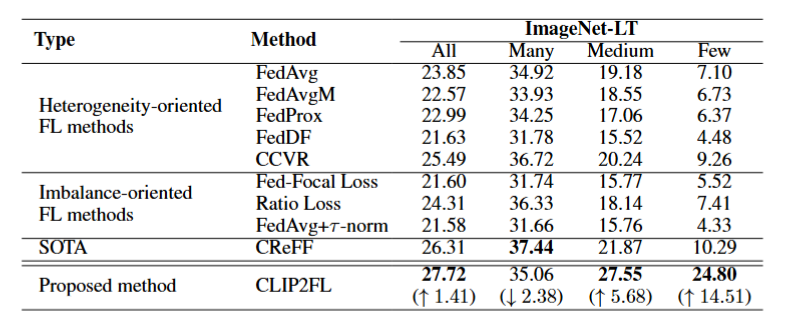
这是作者实验结果。
实验分为20个客户端,数据分布长尾、非iid:
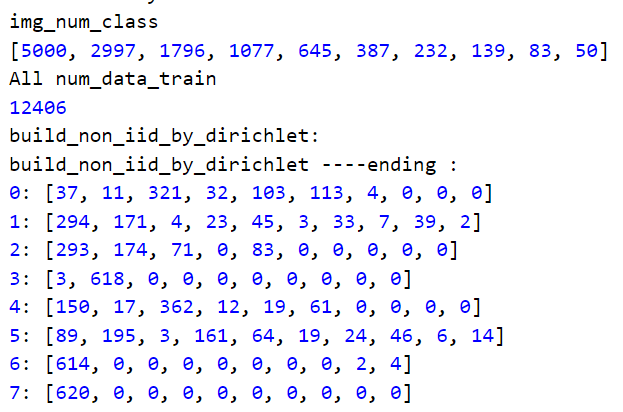
但是本文没有考虑到的是:

没有考虑到设备的异构性,即不同设备的通信能力、计算能力不一样。
