
论文阅读-配备MEC的卫星6G网络中-混合集中-分布式学习
摘要
对于未来的6G网络,需要维护全球连接、向许多地方提供应用、分析大量的数据等等。为此,人们应用卫星网络来到达距离网络核心很远的地方,也有研究调研为这些卫星配备边缘云服务器来为偏远设备提供计算卸载。然而,分析这些设备创造的大量数据是一个问题。可以把这些数据丢到中央服务器,但是传输代价非常高。也可以通过分布式ML方法处理数据,但这种方法又没有集中式方法有效。因此,本文分析了两种方法的代价,然后提出了一个混合式的方案(在一个配备了云服务器的卫星网络中)。本文方法可以为每个设备提供最好的学习策略,且对不同配置可以做出良好的动态反映。
简介
在未来的时代,最重要的是提供无处不在的连接,确保网络达到各种各样的地方。到达这些地方最好的解决方案之一是使用卫星网络。通过使用近地轨道卫星(LEO),该区域设备可以直接或通过使用放大转发中继与卫星通信。LEO卫星足够近以提供可管理的接入延迟,其星座图(constellation)可以连接这些孤立设备,使得一些物联网应用可以在更远的区域运行。
像智能工厂、智能家居、自然传感、军事任务等涉及偏远地区设备的任务都可以得益于LEO接入,这些设备可能由于偏远或者网络基础设施暂时中断而无法接入传统地面网络。这些场景下的服务涉及收集环境数据(如位置信息、温度、障碍物位置),并采取行动,以达到应用效果(如构建产品、保持家居温度什么的)。换言之,IoT设备需要感受环境、提取数据,然后输出一个最优动作。我们常常用机器学习模型训练数据来达到这些目的,但是经常单一设备的数据不够;理想情况下我们会想把数据集中起来,然而设备太多会导致传输所有的数据不够灵活——而且在卫星网络中通信资源很有限,网络带宽和传输功率必须被很好的控制。
于是就有许多工作提出了分布式学习范式,但是其中也有缺点:即分布式训练需要更多迭代来达到收敛。综合考虑,在卫星网络这样的系统中,本文在6G IoT网络场景下,提出一种协议,用于训练一个DQN模型,来优化孤立IoT设备的动作选择策略。这些设备通过放大转发中继连接到一个配备了MEC(多接入边缘计算)的LEO卫星网络。这些卫星们依旧可以到达一个中央云服务器。本文目标是通过一种混合分布式-集中式学习的方式训练一个DQN模型,平衡通信和计算开销。
本文主要贡献:1.本文提出一个解决方案做平衡:在传输成本不高时用集中式学习,在避免远程通信情况下使用分布式学习。2.本文假设的场景不仅考虑了MEC在卫星网络中的应用,还关注了通信和处理方面的综合成本。3.提供了一个计算传输成本的模型。该模型不仅考虑了卫星网络的特点,也考虑了对6G网络的总体期望。
通过LEO卫星进行深度学习
总体假设
假设有N个LEO卫星;相似的,有N个地面cells和其中的一些终端设备(只能看到其中一个卫星)。这些卫星一直在移动,所以他们在timeslots之间从一个cell移动到另一个cell(timeslots长度与这些cell的LEO观测时间相同)。这种移动由轨道决定:cells和卫星被分成轨道,每个轨道上有相同数目的cells/卫星;卫星只在它们轨道的cells上飞行(?cells and satellites are divided into orbits where each orbit has the same number of cells/satellites. Satellites fly above the cells of their orbit only)。此外,由于是轨道,所以这些cells是围绕着循环的(即:当一个卫星到达其轨道的"final cell"时,下一个cell就是轨道的first cell)。此外,卫星只能和同一轨道上的临近卫星通信。地面上有一个中央服务器,可以通过其与每个轨道的一个基站有线连接(this central server is accessible through wired connections between the server and one base station per orbit for each orbit)。这个基站放在我们称之为central cell的cell里。
我们假设central cell没有终端设备(为简化处理)。轨道中的其他cell则配备有终端设备(为简化处理,假设这些单元的终端设备数量相同,且设备在单元内部的位置呈随机分布),并且在这些单元中有一个放大转发中继站,供终端设备接入卫星网络。通过卫星网络,终端设备可以通过星间链路(ISL)连接到central cell可见的卫星,然后该卫星再与central cell的相应基站通信。最终,每个单元可以是一个分布式学习单元,也可以是一个集中式学习单元。分布式学习单元中的终端设备将在LEO卫星的 MEC 服务器上用于训练本地 DQN 模型。集中式学习单元中的终端设备则在地面中心服务器上用于训练全局 DQN 模型。
DQN模型
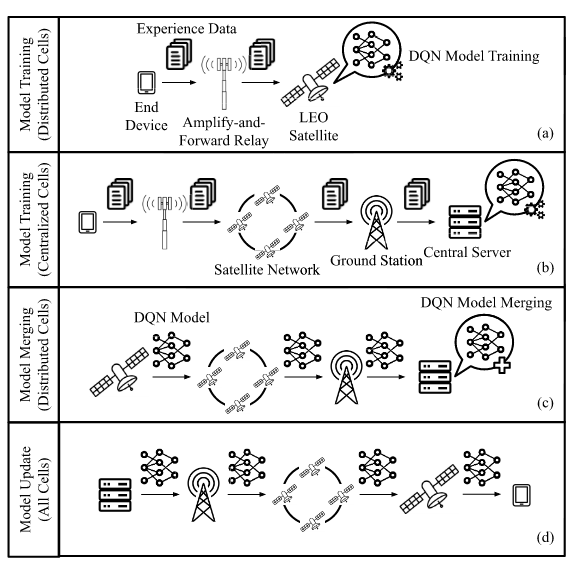
就是说所有的设备执行同样一个任务,就是强化学习里比较经典的走迷宫任务(不知道咋扯上去的。摘要的关键词还有个DQN,我还以为是在进行决策——但现在看来应该就是给联邦学习套一个模型例子。比如,由于DQN这种学习在联邦学习中,可以共享的东西是经验回放;而在联邦生成模型中,比如GAN,可以把生成器、判别器拆出来到边缘设备和服务器)。不同cell的训练方式不同,如图所示:
第一行:分布式cell的模型训练,就在本地LEO的MEC练了
第二行:集中式cell的模型训练,经过星间链路-基站-有线网-中央服务器
第三行:分布式cell进行模型聚合
第四行:所有cell更新(中央服务器下发)
经验传输时延
根据上述所述,可以说最重要的一点就是把经验元组从终端设备发射到服务器。服务器需要经验元组训练,我们需要估计在分布式/集中式的学习cell里它的传输时间。理解这一开销对决定每个cell选择哪个学习很重要。第一步是,把元组从终端发射到中继放大站,然后再经由它送给可视的卫星。按照6G期望,假设NOMA(非正交多址接入)和波束赋形应用,所以传输之间没有干扰。设备到中继站的发送速率为:
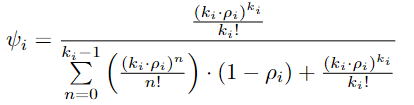
对于位于cell m上方的卫星, μ
表示ISL(星间链路)中的传输时间(忽略传播延迟),其计算方式为
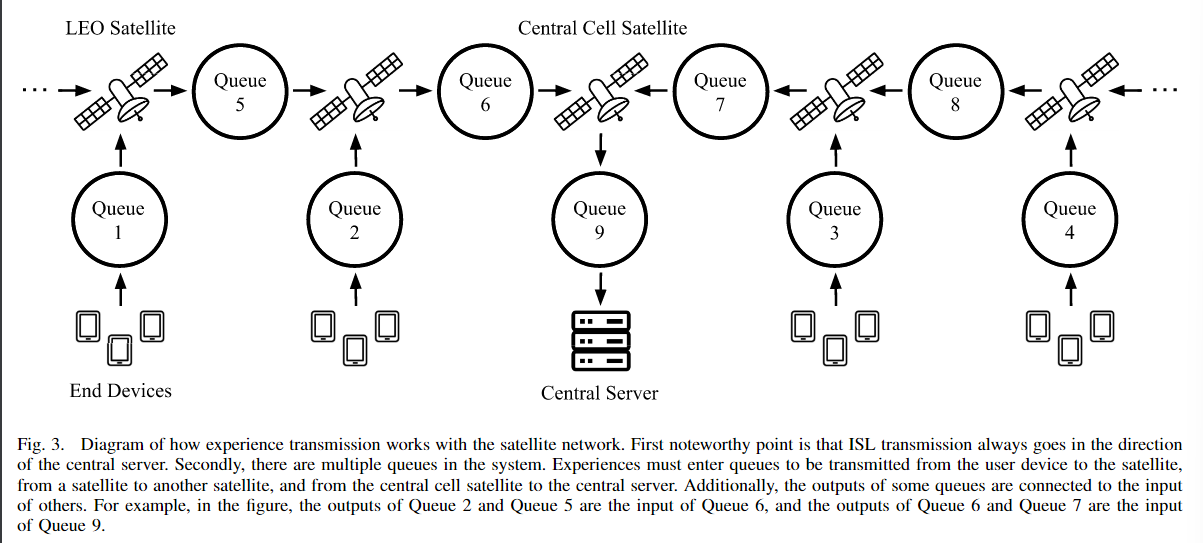
然后据此,作者设想了三种情况:1.边缘小区(cell)卫星:位于直线“链”的两端,即最远离中央小区的卫星。这些卫星仅处理本地小区的经验元组,不需要中继来自其他卫星的数据。2.中间小区卫星:位于两端卫星和中央小区卫星之间的中继卫星。它们不仅接收来自本小区的经验元组,还需要中继来自更远离中央小区的卫星的元组。这些卫星的队列负载可能会较高,因为它们需要处理其他小区的传输。3.中央小区卫星:位于“链”的中心,连接至中央服务器。这一卫星仅接收来自各卫星转发来的经验元组,不发起新的经验元组,且最终将数据传输至地面基站。根据这些情况建模了传输时延
学习成本
以传输延迟(即将经验元组从卫星发送到执行学习的服务器)和处理延迟(即利用经验元组训练模型)为基础。对于DQN,学习是通过在服务器上随机抽取重放存储中的数据来进行的。因此,一旦经验元组被添加到replay池中,并不一定会立即用于训练(尽管这种概率相当大)。此外,在分布式学习环境中合并不同模型时,通常会有部分信息丢失(换句话说,即使使用相同的总迭代次数和相同的经验,分布式学习和集中式学习的训练结果并不完全相同)。因此,在确定每种学习范式的成本时,适当的做法是对传输延迟和处理延迟进行加权求和,以便在处理延迟较重要或较不重要的情况下灵活调整各方的影响。公式如下:
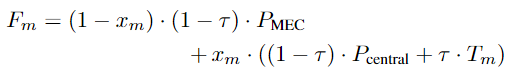
两个P是在对应地方训练DQN单次数据需要的时间。xm的意思是,是中央cell就是1,否则是0.
问题求解
目标就是最小化
由于本文实在是写的晦涩难懂,就总结点东西。一个是,虽然说的是结合分布式和集中式训练,但其背景就是每个设备要训练一个DQN:这种具体的强化学习模型,由于其可以离线学习地使用“经验回放池”,具备天然的“收集各分布式数据”的条件,所以可以采用分布式训练的框架(本文并未讨论异构情况)。
本文实验证明了,其收敛所用的通信时延比集中式要快,且收敛程度是一样的。
此外,关于6G,一个是系统模型背景接近(覆盖能力强),另外是文章几处涉及到:“Following 6G expectations, we will assume that NOMA and beamforming are utilized so that there is no interference between transmissions ";"Path loss is obtained by considering a model characteristic of millimeterwave channels, like the ones expected to be seen during 6G"。此外,文章的模型参数也来自近期一些关于6G网络文章中期望的参数。
