边缘计算与强化学习简述
本文主要概述两篇相对早期的应用RL于边缘计算的论文。
文章一
第一篇是2019年的,题目是Smart Resource Allocation for Mobile Edge Computing: A Deep Reinforcement Learning Approach | IEEE Journals & Magazine | IEEE Xplore。
摘要
资源有限的移动设备面临着前所未有的严重容量限制,移动边缘计算(MEC)是一种有前途的解决方案。然而,MEC也有一些局限性:基础设施部署和维护的高成本,以及复杂多变的边缘计算环境。在这种情况下,重点在于:在变化的MEC条件下合理分配计算资源和网络资源以满足移动设备的需求。为了解决这个问题,我们提出了一种基于深度强化学习的智能资源分配(DRLRA)方案,它可以自适应地分配计算和网络资源,减少平均服务时间,并在变化的MEC环境下平衡资源的使用(文章主要考虑的是环境的突然变化性)。
系统建模
在无线通信的这些问题中,首先要做的就是对具体问题进行问题的建模。本文的系统建模图:
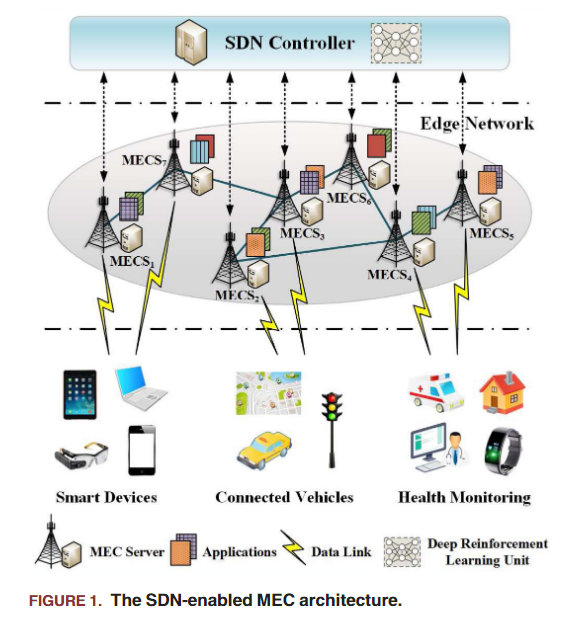
本文提出了一个SDN支持的MEC架构,SDN实际就是一个DRL网络来进行调度。边缘网络建模为一个图G(V,E),V是MECS(MEC服务器)集合,E是数据链路。定义大量移动设备的应用请求为一个集合M。这里,不同的MECS负责不同的应用,比如有个任务给到了a号MECS,但是它干不了,就要把请求路由给b号MECS。
本文目标是最小化分布在不同区域的移动设备生成的所有请求的平均服务时间(包含边缘网络中的请求路由延迟和托管所需应用程序的相应 MECS 中的数据处理延迟),并明显平衡每个MECS的计算负载和数据链路上的网络负载。因此,本文的问题定义就包含四个需要考虑的量:路由延迟、数据处理延迟、网络资源分配方差和计算资源分配方差(后两个是为了平衡网络用的,就是说,不能全都堆到一个MECS上,计算资源也要均匀一点)。
具体的公式定义不是很重要,总之最终的优化目标就是两点:1.最小化平均服务时间;2.平衡网络资源分配。对于(1),定义为:
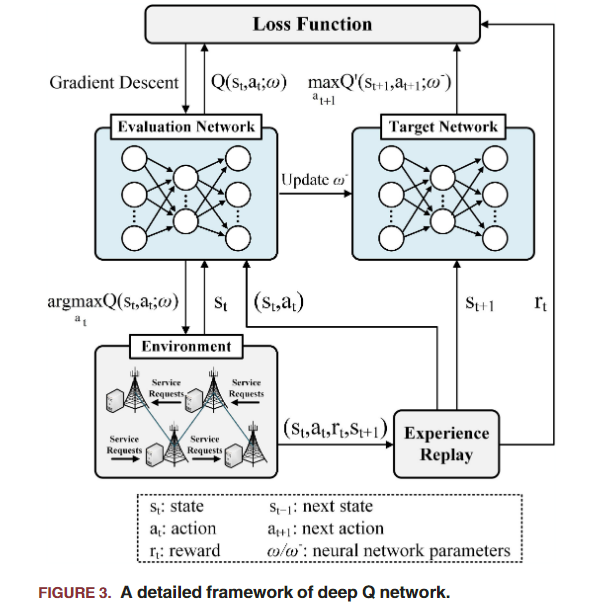
DRL框架
其实就是最基本的DQN框架:
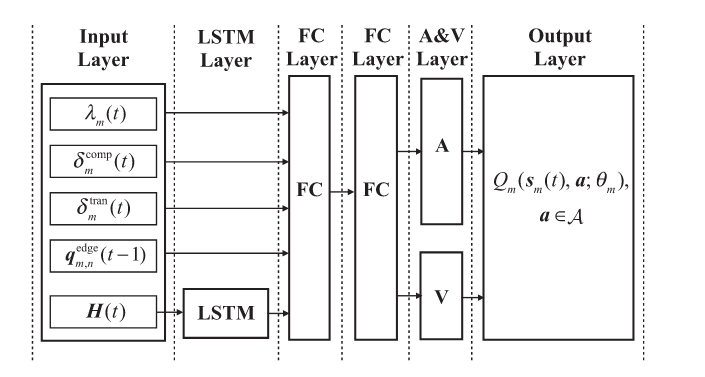
这种基于强化学习的方法都要定义state
action和reward,本文的reward也自然和优化目标相关,为
文章二
第二篇文章:Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems | IEEE Journals & Magazine | IEEE Xplore,着重考虑MEC系统中的任务卸载(感觉都差不多,计算任务卸载也即移动设备将其计算任务卸载到附近的边缘节点进行处理;上文提及了计算卸载但主要聚焦于环境的多变性)。这是一篇2020年的,可以看做对上一篇的进一步延伸。
摘要
在移动边缘计算系统中,当大量移动设备将其任务卸载到一个边缘节点时,该节点可能会有很高的负载。这些卸载的任务可能会遇到较大的处理延迟,甚至在截止时间(即问题的约束之一)到期时被丢弃。因此,出于这种边缘节点上不确定的负载动态,对于每个设备来说我们需要考虑:是否卸载,以及应该将任务卸载到哪个边缘节点。本文考虑了不可分割的和延迟敏感的任务以及边缘负载动态,并制定一个任务卸载问题,以最小化预期的长期成本。本文算法使得每个设备可以在不知道其他设备的任务模型和卸载决策的情况下确定其卸载决策。比起上文模型,本文模型改进在于:结合了LSTM、对战深度Q网络(Dueling DQN)和双DQN技术。
系统模型
本文系统建模定义的参数很多,不仔细介绍了。系统图为:
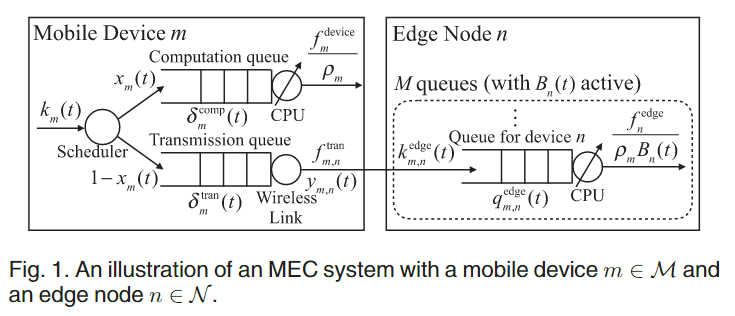
简单讲即:首先第k个任务来到移动设备m,调度器决定它是本地计算还是计算卸载出去;如果计算卸载就放到传输队列里,等轮到这个任务就通过无限链路传到 某边缘节点。
总之,定义了到达任务的bit量
action则包括两项:是否卸载任务,以及卸载到哪个节点。其空间为离散的、N+1大小的{0,1}。至于reward则有由理时延决定,如果任务超时被drop了,那么就定为一个惩罚项C。于是有了网络框架: