
论文阅读-基于扩散模型的强化学习应用于边缘AIGC服务(的调度)
摘要
背景:元宇宙时代,AIGC技术至关重要,但资源集中,需要分配。本文介绍了一个AIGC-as-a-Service
(AaaS)
架构,把AIGC模型部署到边缘网络来确保让更多用户使用AIGC服务。尽管如此,为了提升用户个性化体验,需要仔细地选择能高效执行任务的AIGC
Service Providers
(ASPs),这一问题因为环境不确定性和变化性而变得复杂。为此,本文提出了AI-Generated
Optimal Decision
(AGOD)算法,一个基于扩散模型的方法,用来生成最优ASP选择决策。将AGOD与Deep
Reinforcement Learning (DRL)结合,作者提出了Deep Diffusion Soft
Actor-Critic (D2SAC)
算法,提高了ASP选择的高效性(大致即,扩散模型用作SAC中actor网络,用来从一个高斯噪声中生成策略
简介(大部分灌水)
目前AIGC很重要,但是训练部署成本很高,限制了其广泛应用。其次是AIGC要为不同用户生成个性化内容。因此AIGC下的元宇宙有两个目标:1.让任何设备在何时何地都能用;2.其服务能够最大化用户体验。为实现目标(1),AIGC被部署在边缘网络上,用户上传需求然后拿到结果。对目标(2),不同AIGC生成偏好不同,用户兴趣和服务器计算能力也不同,因此要为用户选择最佳的ASP,设计高效的调度算法。然而,对用户效用(user utility,大概可以看作用户满意度)和AIGC模型能力进行数学建模并不容易。本文提出了一种diffusion model-based AI-Generated Optimal Decision (AGOD)算法,来用扩散模型在不确定和变化的环境中生成最佳决策。本文贡献在于:
1.提出了AaaS架构(解决目标1);2.提出AGOD算法(解决目标2);3.把AGOD用到了DRL(SAC算法)中,最大化用户的主观体验。
相关工作
无线网络中的AIGC服务
Aaas
本文以图像生成为例,其架构如图所示。
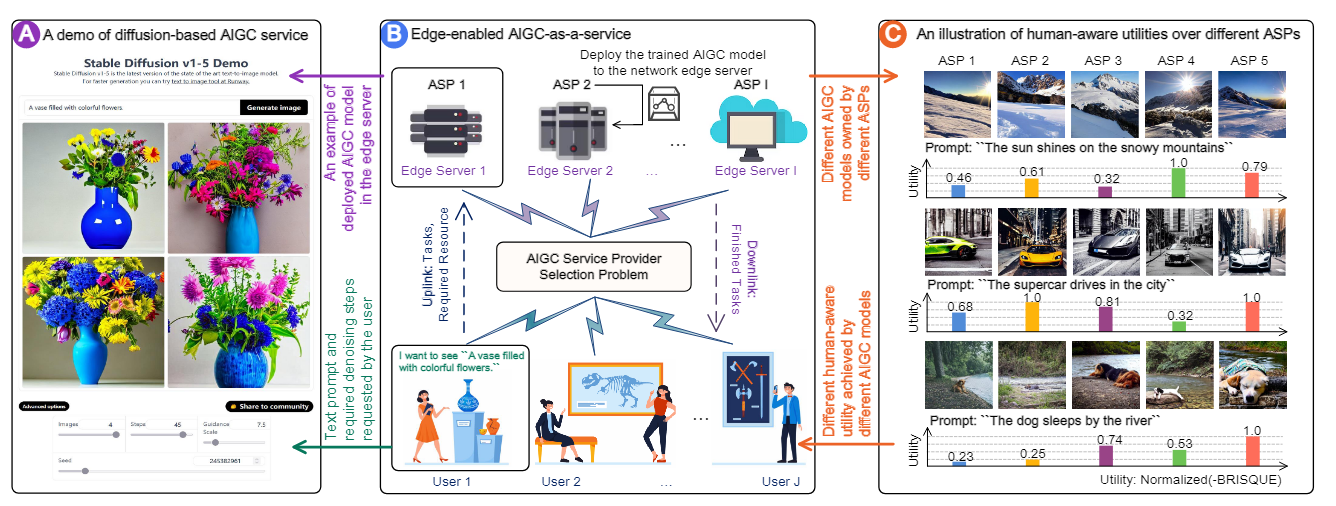
其实就是用户发送需求(如prompt和去噪步数),然后选择边缘网络的合适ASP执行任务并返回。不同ASP有不同的图片生成风格,用户也会因此收到不同的效用(图中是BRISQUE衡量的,即模型无参考评价模型)。
ASP选择问题
ASP选择问题与资源约束下的任务分配问题类似,旨在分配任务到可用的资源,并在满足约束的前提下最大化整体效用。
问题建模:一组序列任务
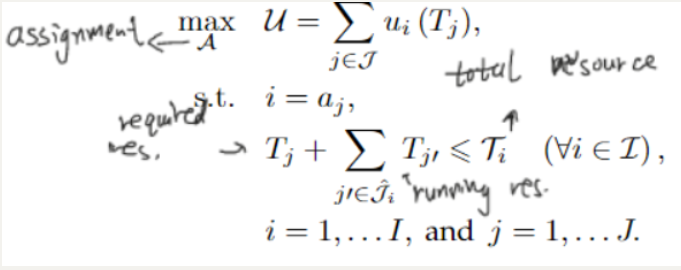
难点:任务是动态的实时变化的,不能提前知道;效用值不仅取决于用户主观感知,也取决于分配给的ASP的性能,在调度时是未知的。
human-aware utility function
用户任务的效用值无法提前获知,它需要由一些应用于AIGC的评估技术决定,可定义为:
AI生成最优决策
AGOD的动机
ASP选择问题的解空间是有穷、离散的,解空间大小随变量数量而指数增长;一些RL方法难以应用。受DDPM启发,本文旨在提出一个基于扩散模型的优化器来生成这种离散性质的决策方案。即,根据扩散模型,当前环境下的最优决策加入噪声直到变成高斯噪声,然后在逆向过程中根据环境
前向过程
由于缺少最优决策解的数据集,AGOD没有前向过程。(通过奖励训练)
逆向过程
具体实现AGOD时,我们先计算逆向转移分布
基于扩散模型的强化学习
问题建模
1.状态空间。状态s(即agent的观测)包括两个特征向量:一个代表将要到来的任务
2.动作空间。动作空间很好理解,就是从1到I的整数空间。在评估过程中,动作a就等于
3.奖励函数。奖励包括两部分:AIGC质量奖励
此外,指定状态转换的最大数量L,来指示一个trajectory的终止。通过上述定义,我们的总体目标就是训练AGOD网络的参数
算法架构
包括一个actor,一个double critic,一个target actor和target critic,一个experience replay和交互环境。
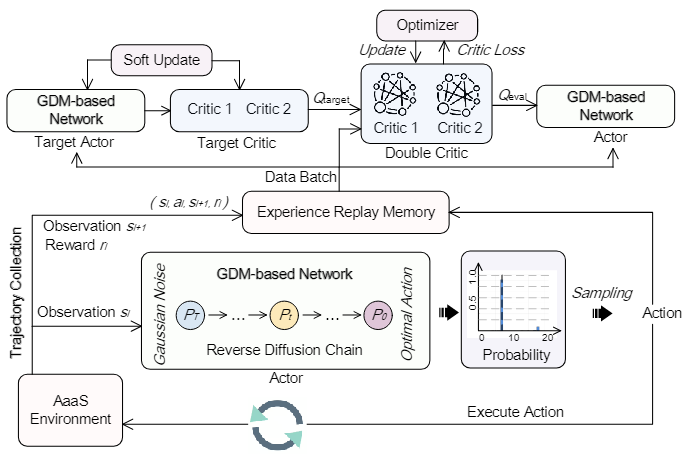
本文用了两个Q函数来进行policy evaluation,两个Q函数有各自的独立参数,并且独立更新。训练期间,估计的Q值是二者的最小值,这一方法确保actor根据Q值的保守估计进行更新,更加稳定高效。
考虑到正则化,actor要最大化的式子就可以写成:

