
论文阅读-分布式强化学习应用于车联边缘计算中的联邦学习
摘要
本文的背景是联邦学习与车联边缘计算(vehicle edge computing, VEC)。联邦学习共享车辆本地模型的梯度而非数据本身,这样的意义是可以保护数据隐私;但模型梯度通常很大,传输延迟会很高,因此有人提出梯度量化的方式,即压缩梯度、减小比特数(即量化等级)来传递梯度。影响模型精确度和训练时间的指标主要在于:量化等级和阈值的选择,因为二者决定了量化的误差(quantization error,QE)。因此,总训练时间和量化误差QE就成了FL驱动的VEC中的关键指标,也即强化学习方法需要最大化的奖励。此外本文也建模了一种挑战,即时变信道条件。
简介
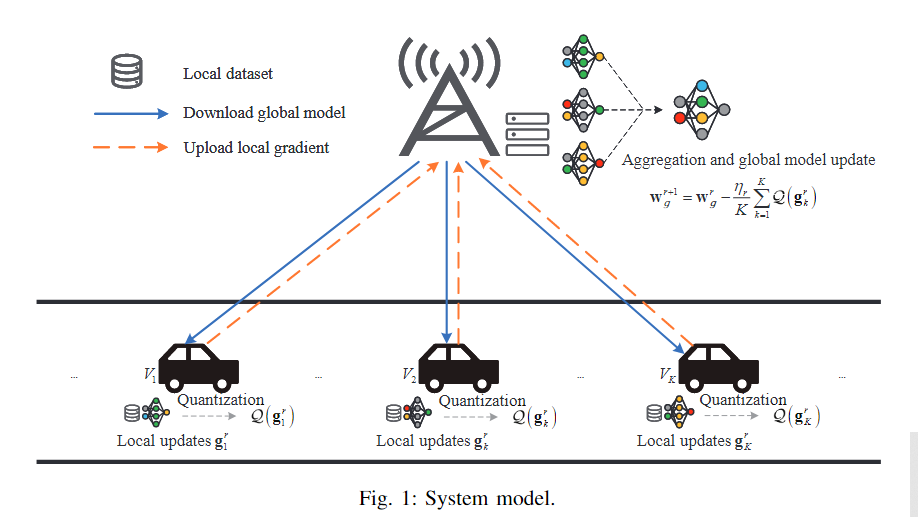
总之就是说,车辆上传感器很多,所以产生数据很大(1G/1s)。因此车辆需要强大的算力来处理数据,但显然这是有限的,因此就用一个基站来连接边缘服务器吗,收集利用这些数据(的梯度,以防隐私泄露)进行训练。即,在每一轮训练中,所有汽车先用本地数据训练本地模型,然后BS收集本地模型的梯度并聚合成全局模型,再之后边缘服务器把全局模型发送给车辆进行下一轮训练。
由于梯度大,我们需要采用梯度量化来减少传输梯度需要的时延,减小训练时间;但量化水平太低又可能增加收敛时间,以及让模型不准确。此外,由于车辆是在路上动的,所以带来时变路径损耗。
DRL可以解决复杂环境里的这些问题。为什么选择分布式DRL呢?现有一些方法是集中式DRL处理的,这种框架流量负载高、且因为车辆移动性高所以BS难以收集准确的CSI。而在分布式DRL中,每辆车独立决策,无需发送所有信息到中央结点,减少了通信开销。
系统建模
AI通信最重要的地方之一就是要构建一个系统模型场景,也就是做出一个environment simulation。来看看这篇文章是怎么建模的:
考虑有N个车辆,记作
总之,这个系统环境输入V个车,输出优化后的全局模型w。环境的流程是:
1.初始化全局模型
2.在每一个round中,每个车下载全局模型;
3.每个车获得其移动信息x和v,即当前所处位置和速度,然后据此算出在BS覆盖范围内的停留时间(residence time);然后接受一个全局消息,即一个round的时间和决策阈值;
4.每个车根据本地与全局模型的相似度和停留时间,算出其效用utility;
5.每个车看看这个效用是不是超过决策阈值,超过了就选中,否则不选;
经过2~5,得到了选中的集合
1.先算用全局模型下,本地数据集D得到的损失;
2.根据这个损失值,得到本地的梯度;
3.量化本地的梯度。
然后,每个车把量化的本地梯度和本地损失函数送到BS。BS聚合这些梯度,然后更新全局梯度、计算全局损失函数:
问题建模
在建模和系统模型后,就要对问题进行建模,即确定需要优化的目标以及约束。这些都是DRL框架中设计reward需要的。
训练时间
FL中 每一轮第K个车的训练时间包括:本地训练计算时间、上传时间、全局聚合梯度时间(很快可以忽略)、下载时间(很快可以忽略)。
训练计算时间:由车辆更新样本需要的cycles数和CPU的频率决定。
上传时间:由量化后需要上传的bits数和传输速率决定。这里的传输速率和Shannon
theorem有关:
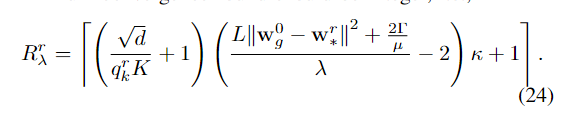
量化误差
由模型大小、第k车的量化等级和第r轮的本地梯度有关。定义为:
优化问题建模
我们现在阅读的论文都建模出了一个优化问题,且这些问题都是非凸的、不能用传统方法解决的。比如这篇论文建模问题为:
分布式DRL解法
在最后,根据建模出的优化问题,决定DRL框架的state、action、reward,然后采用合适的算法。在每一个round的时间步t,每个被选择的Vk观测到局部状态并根据策略做出动作。注意,这里的Vk是之前每轮筛选出的车辆集合。
状态
状态通常来源于system
model、问题约束。本文状态由下面项组成:Vk车与BS的距离
动作
即第k个车在t时刻选择的量化等级,是一个[2,...,10]的集合。
奖励
就是优化目标取负(因为优化目标是最小化,所以reward要最大化),然后算一个episode里的累积期望。
在强化学习框架上,本文选择了DDQN算法,其框架如下:
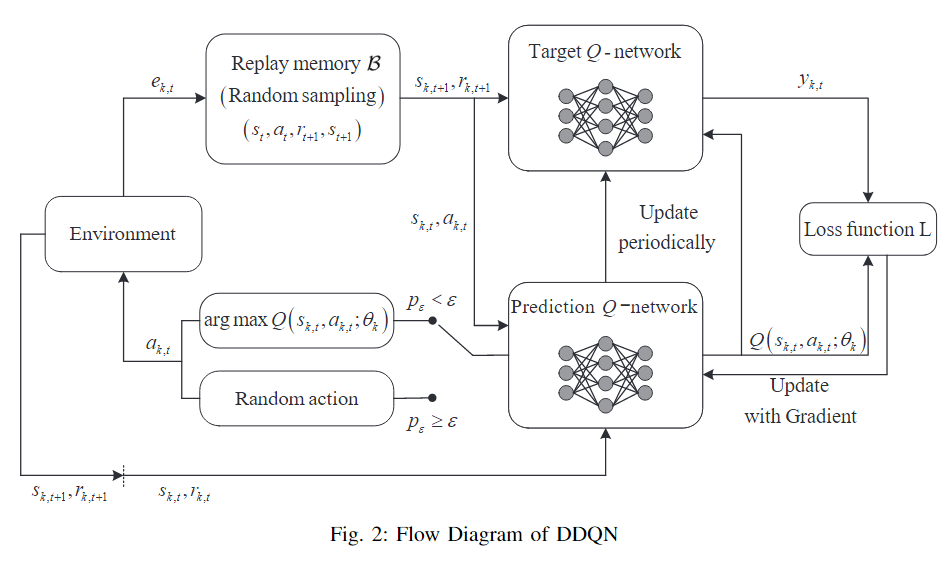
P.S. : DDQN的critic和actor可以看作是一起的,因为它是直接根据最大Q值选动作,而不是输出一个分布。
总结
AI+无线通信决策,大致分为以下阶段:1.选择问题背景;2.根据通信背景进行system modeling;3.找出建模场景中,需要优化的目标和约束;4.利用DRL框架,找到建模的system中的state和action,然后根据优化目标和约束设计reward;5.设计合适的DRL算法。
这篇文章用的是动态车联网环境下的。可以考虑一个静态环境:
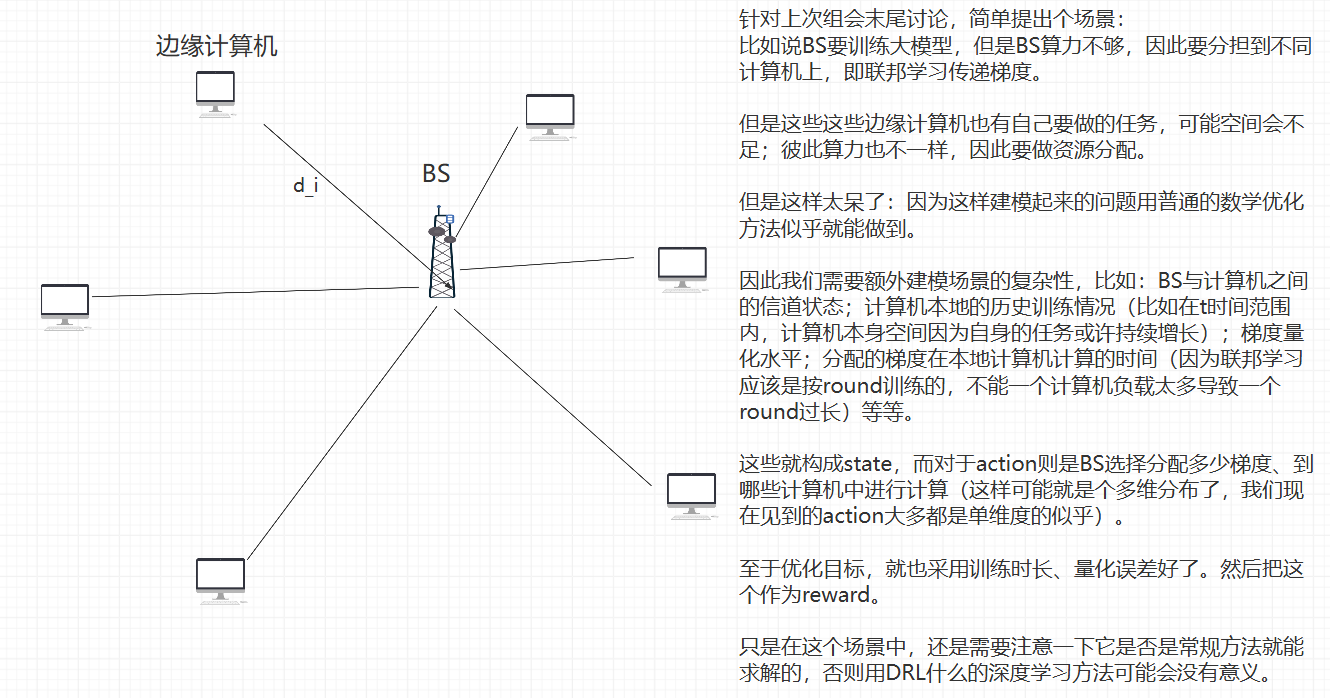
note: 信道共享;信道衰落、噪声与去噪;优化目标的确定
