
HOI琐碎闲聊(二):HICO-DET数据集分析
最近在利用stable diffusion模型人工生成数据集,我们知道,HICO-DET包括117种动作,600种hoi类别,这600种hoi类别有着非常明显的长尾分布问题,如图所示:
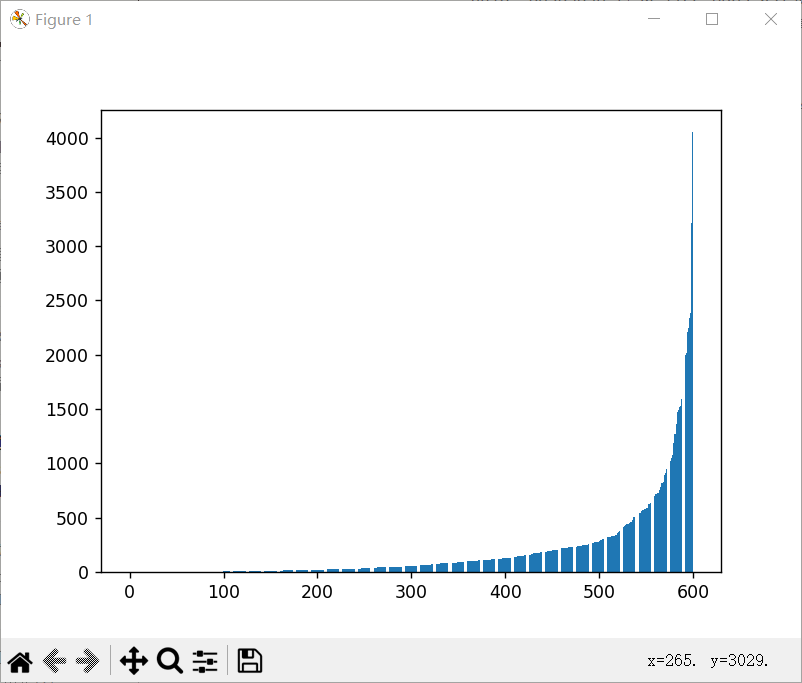
至于动词,也有着很明显的长尾分布,不过我们主要考虑hoi三元组的分布。可以看出,大概前160个类别的数量非常稀少,我们打印出这160个类别对应的prompt的一部分(大概70个):

使用扩散模型生成虚拟数据集时,可以利用clip再过滤。以下是使用CLIP计算相似度结果,前者是正常配对,后者是错误配对(每个图片与上一个图片的提示词配对):
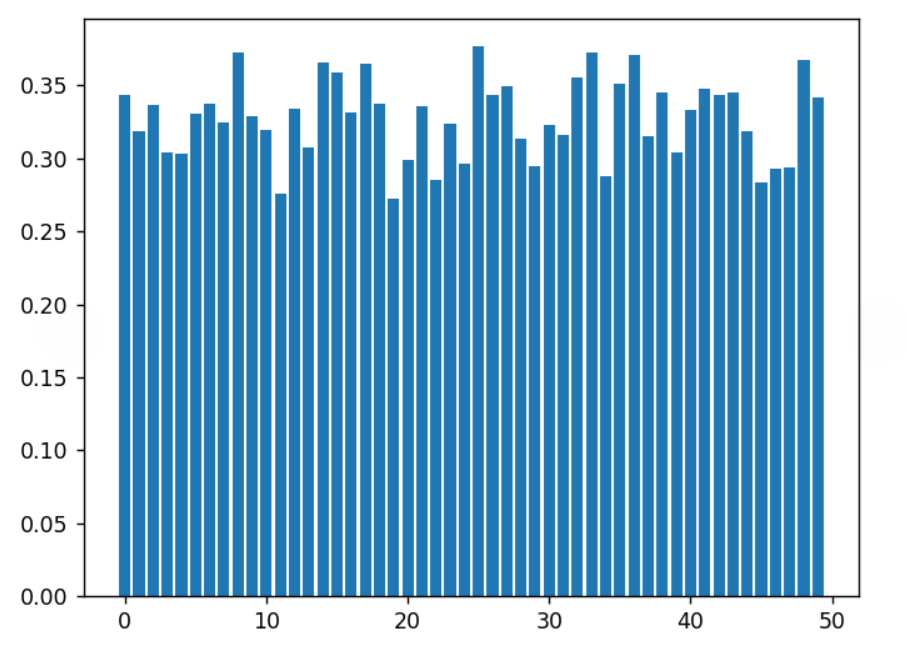
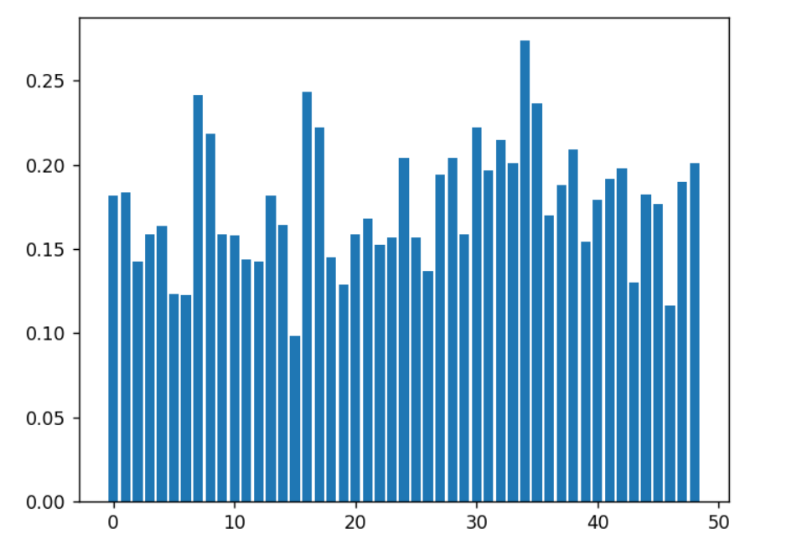
可以看出,我的实验中,大致的分水岭是0.25。进一步取500个图,画两张图:一种编码的text是非完整的prompt,只包括动词名词;另一类是原生prompt,结果见下。上图是非完整的,下图是完整的。
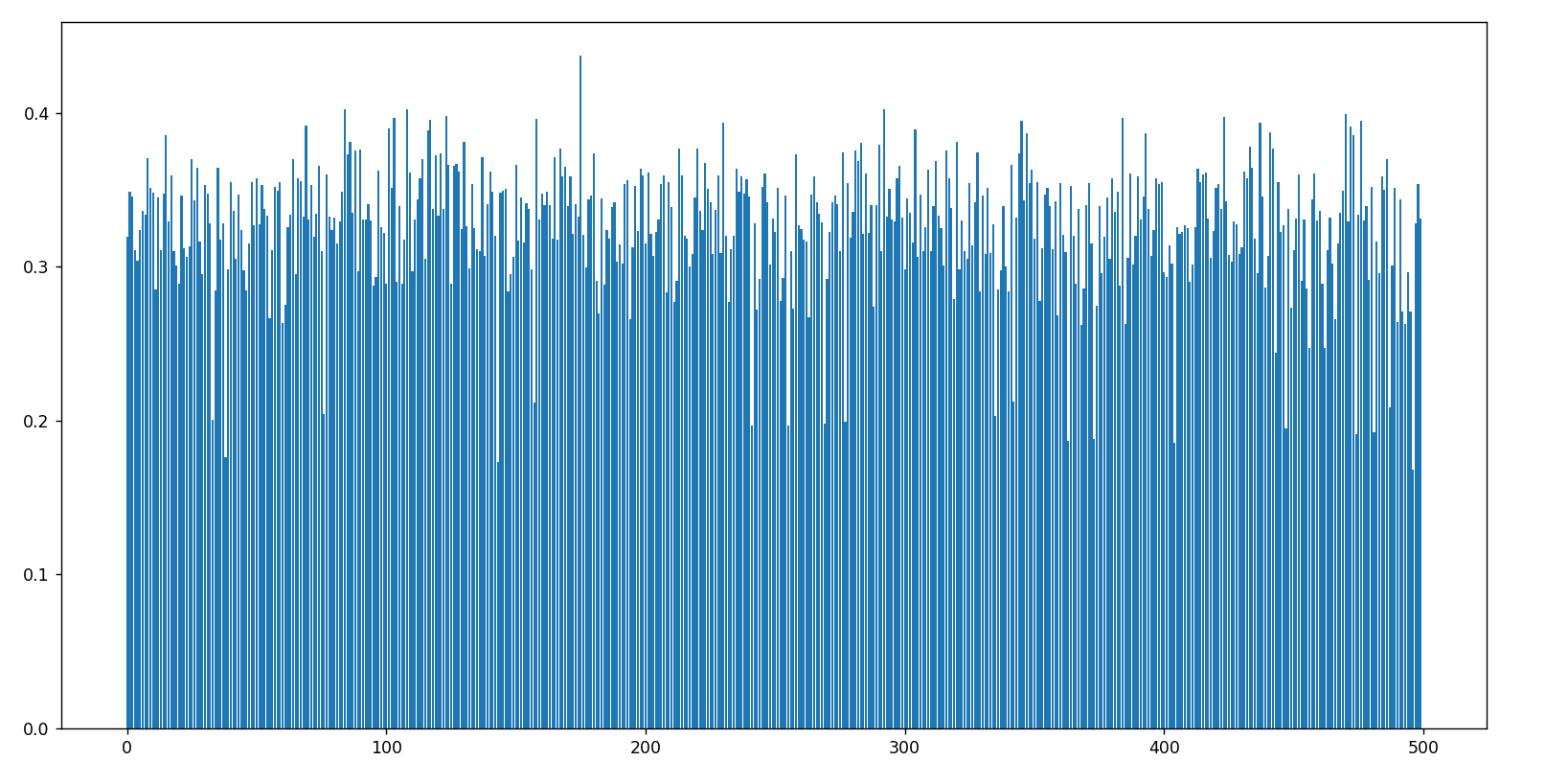
二者基本无差。再检查低于0.25的图片时,一个神奇的现象是:大多数图片都是no interaction的图片,比如:

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 雨白的博客小屋!
相关推荐

评论