
人-物交互检测(一):HOTR
人物交互检测是检测图像中人、物体以及其交互关系的任务。目前常用的数据集有HICO和V-COCO。在很多年前,transformer还没有流行的时候,一些做法是:先利用faster rcnn等提取出人、物的bbox,然后利用姿态特征提取网络(如openpose)提取人体姿态特征,然后再根据这些特征判断交互类别。显然这些做法比较低效,需要额外的后处理(相关论文可见:朴素实现的人-物交互(HOI)检测-论文阅读 | 雨白的博客小屋 (ameshiro77.cn),不过我没写完)。后来,transformer提出以后,也被成功的应用到了目标检测上(例如DETR),自然而然也被尝试利用在了人-物交互检测里。
本篇主要阅读HOTR论文,但是实际上这项工作的效果并不是太好。并且,现有HICO数据集长尾现象严重,在之后的博客我们会看到:最新的工作利用扩散模型等AI生成技术,扩充数据集,来达到更好的训练效果。另外,十分建议看本文前先看DETR,因为之后的QPIC和HOTR都跟DETR太像了。
论文链接:[2104.13682] HOTR: End-to-End Human-Object Interaction Detection with Transformers (arxiv.org)
--------分割线--------
简介
HOI,即Human-Object Interaction,人物交互,它的检测任务就是定位图像中主体(人)和目标(物体),并且对其交互关系进行分类。在此之前的方法通常是:先检测出人和物,然后对每一对检测出来的人/物做单独推断。本文则提出了一种基于transformer的新的框架:HOTR,可以直接预测一系列<h,o,i>三元组的集合,它充分利用了图像中固有的语义关系,而不需要额外的后处理过程。总的来说,本论文的贡献为:
1.提出了HOTR,首个HOI检测的基于transformer的集合预测方法。它消除了手工的后处理过程(比如基于IoU的启发式方法,或用另一个神经网络代替),能够建模交互之间的相关性。
2.本文提出了各种训练和推理技术:HO指针用来关联两个并行decoder的输出;一个重组步骤来预测一组最终的HOI三元组;一个新的损失函数来实现端到端训练。
相关工作
HOI检测早期分为顺序方法和并行方法。顺序方法中,先进行目标检测,然后对每个检测出来的目标对,再用一个单独的神经网络推断其相互作用。在并行方法中,HOI检测器并行执行目标检测和交互检测,然后利用启发式方法把它们联系起来,比如利用IoU、距离等等。具体在此就不再赘述。
另外一个相关工作就是DETR,读者可以自行研究。
方法论
本文的目的是以一种端到端的方式,在考虑<h,o,i>三元组之间固有语义信息的前提下,预测一个hoi三元组的集合。首先,作者讨论了将用在目标检测的集合预测架构直接扩展到HOI检测上的问题。然后,作者提出了HOTR架构,并行地预测一组目标检测集合、关联人与目标间的交互,同时用transformer里的自注意力机制建模了交互之间的关系。最后,作者展示了训练中的细节,比如Hungarian Matching(匈牙利算法,用于匹配二部图);以及损失函数。
集合预测形式的检测
首先作者以transformer为基础的,集合预测形式的目标检测任务开始,然后展示了如何扩展这个架构到HOI任务。
Object Detection as Set Prediction
这种方法也就是大名鼎鼎的DETR所用的。因为目标检测对每个物体包括一个分类和一个定位,因此DETR的transformer编码-解码架构将N个positional embeddings转化为了一个集合,包括:N个物体类别预测,N个bounding box预测。
HOI Detection as Set Prediction
与目标检测类似,HOI检测也可以被定义为一个集合预测问题,每个预测包括一个人类区域定位,一个物体区域定位,以及他们之间多标签的分类。作者简单的扩展是,修改DETR的MLP头,来转换每个positional embedding,以预测一个人类box、物体box和动作分类。然而,这样架构有一个问题:对相同object的定位,可能需要多个positional embeddings的冗余预测。比如:同一个人坐在椅子、在电脑前工作——两种不同查询需要对同一个人冗余回归。
HOTR架构
先上图:
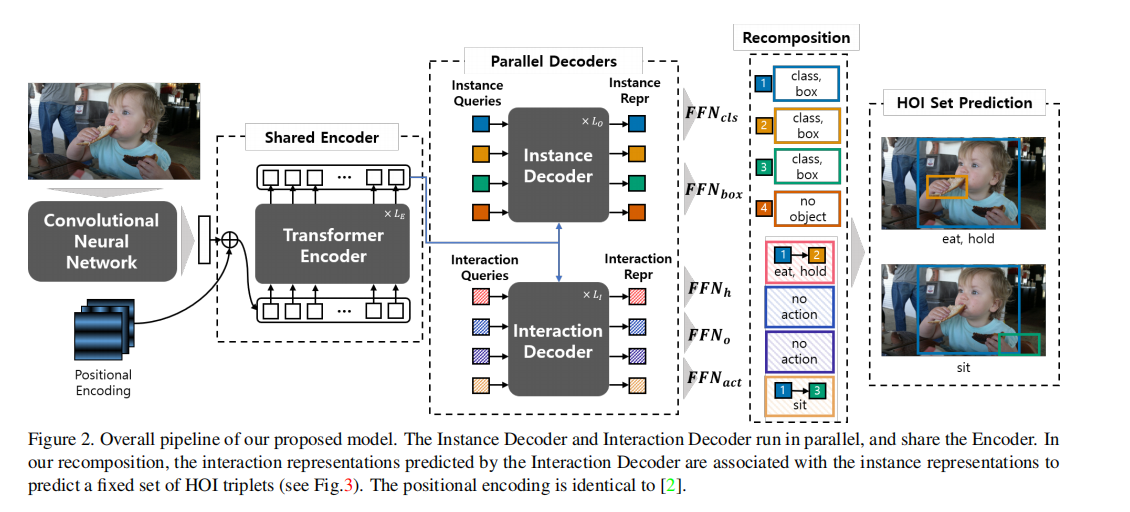
HOTR整体pipeline如图所示。架构特点是一个transformer 编码-解码架构:一个共享编码器和两个平行解码器。两个解码器的结果使用作者提出的HO指针(HO Pointers)关联起来,来生成最后的HOI三元组。
Transformer 解码编码架构
与DETR类似,输入图像的全局上下文用一个骨干CNN网络和共享编码器提取。之后,两组positional embeddings(也就是instance queries和interaction的queries)被送入两个平行解码器(也就是instance解码器和interaction解码器)。instance解码器把instance queries转化为用于物体检测的instance representation,interaction解码器把interaction queries转化为用于交互检测的interaction representation。作者把前馈神经网络(FFN)用在interaction representation上,得到一个Human Pointer,一个Object Pointer,一个interaction type,如图:
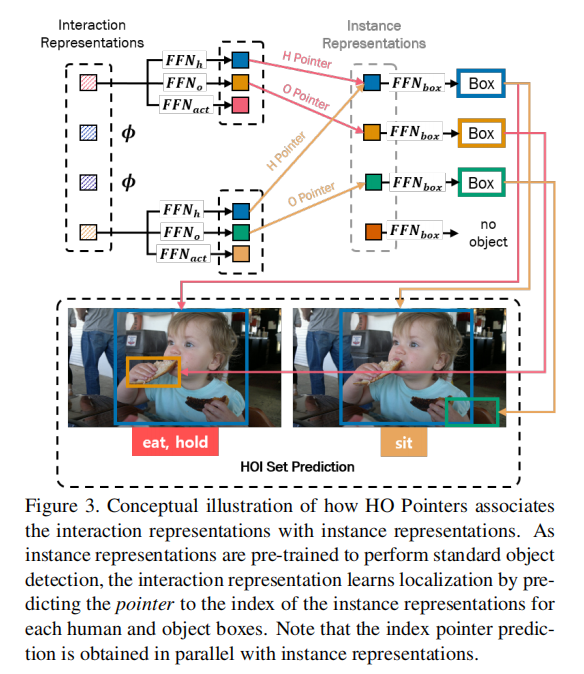
换言之,interaction representation通过使用HO Pointers指向相关联的instance representation,来定位人、物区域,而不是直接回归bounding box。这样的架构比起直接回归bb有几个优点。作者发现,当一个object参加多个交互时,直接回归会有问题:相同object的定位在不同的交互里是不同的。作者提出的架构通过分离instance和interaction的representation,并且用HO指针联系起他们,解决了这一问题。同时,作者的架构也让学习定位更高校,不用对每个交互冗余地学习定位。同时,作者实验证明:共享编码器比两个分离编码器会更高效地学习HO指针(的关联关系,应该是)。
HO Pointers
上图已经说明了HO指针是怎么关联起来两个解码器的预测的。HO指针包含交互中人/物的相应的instance
representations的索引。在交互解码器把K个交互查询转换成K个interaction
representations之后,一个interaction representation
Recomposition for HOI Set Prediction
经过之前步骤,我们获得了:1.N个instance
representation(记作μ);2.K个interaction
representation(记作z)和它们的HO指针。给定γ个交互类别,作者的重排(recomposition)就是把FFN用于bounding
box回归和action分类。这俩FFN记作:
Complexity & Inference time
反正就是消除了后处理阶段,比如NMS什么的,推理时间减少了4~8ms。
训练HOTR
本节里,作者解释了HOTR训练的细节。首先作者介绍匈牙利匹配的代价矩阵cost matrix,用于真实HOI三元组和HOI预测集之间的唯一匹配。之后,使用匹配结果,定义HO指针的loss和最终训练loss。
HOI检测的匈牙利匹配
HOTR预测K个HOI三元组,包括人框,物框和a个动作的二分类。也就是说,每个预测捕捉了一个唯一的<h,o>对,以及一个或多个动作。K被设置为大于图像中交互对典型数量的值(很像DETR对吧)。作者从定义了一个<在真实三元组和预测三元组之间的最优二分匹配>的基本代价函数开始,展示了他们是怎么把匹配代价修改用于interaction representations。
令Y表示真实三元组集合,
于是,令
令M∈R(dxN)为一个归一化instance representation
μ'=μ/||μ||∈R(d)的集合。也就是,M=[
给定真值yi=(bh,bo,a),Ph,Po,作者通过
HOTR最终集合预测loss
然后作者最上述所有匹配对计算匈牙利损失,对HOI三元组的liss有定位loss和动作分类loss,即:
定义HOTR里的No-interaction
在DETR里,最大化softmax输出的no-object class的概率,自然抑制了其他类的概率。但是,HOI检测中,动作分类是多标签的。每个动作看作独立的二分类。由于没有可以抑制冗余预测的显式类,HOTR最终对相同的<h,o>对会有多个预测。因此,HOTR设置了一个显式类来学习交互性,即:认为ho对有交互作用就是1,没有就是0,抑制交互性得分低的冗余交互对的预测,作者定义为No-Interaction class。作者的实验证明了这样会提高性能。
实现细节
自己看吧

实验
这里就不贴了。后话:其实现在来看性能没那么好。

