
人-物交互检测(二):QPIC
论文地址:[2103.05399] QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information (arxiv.org)。本篇和上一篇HOTR非常相似,同时也建议大家多看看DETR。
摘要
作者提出了一个简单直观又强大的HOI检测方法。HOIs在一个图像空间的分布十分多样,现有的基于CNN的模型主要有以下三个缺点:1.不能利用图像全局信息;2.依赖人为定义的局部特征聚合,有时不能覆盖一些重要的上下文相关区域;3.如果HOI实例离得很近可能会混合在一起。 为了解决这些缺点,作者提出了基于transformer的特征提取器,其中注意力机制和query-based detection起到关键作用。注意力机制在全图范围内聚合上下文相关的关键信息非常有效;同时呢,作者设计的query——每个query可以捕获最多一个h/o对——可以避免混合多个hoi实例的特征。这个基于transformer的特征提取器产出很有效的embeddings,使得后续检测头可以相当简洁直观。广泛的分析表明,这个方法成功提取了关键的上下文信息,并且大幅度地提升了性能(5.37mAP在HICO,5.7mAP在V-COCO,注:V-COCO是最早提出hoi的论文(2015年)给出的数据集,当时这个任务叫Visual Semantic Role Labeling ,VSRL)。代码:hitachi-rd-cv/qpic: Repo for CVPR2021 paper "QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information" (github.com)
简介
HOI检测任务因为它在深层场景理解的潜力而备受关注。HOI的任务可以被表示为:<hbb,obb,ocls,acls>。(我相信读者知道这啥意思)
传统的检测方法大致分为两种:两阶段和单阶段。两阶段方法(如no-frill,)里,先首先单独由现成的目标检测器定位人/物,然后用定位区域的特征预测动作类别。为了合并上下文特征,经常利用人/物框联合区域的辅助特征、bbox的位置信息等。单阶段方法(如PPDM)就使用启发式的方法预测交互,比如人-物中心点的中点。
两阶段和一阶段的方法都有显著改进,但由于CNN的局限性和使用CNN特征的启发式方法,都多多少少会遇到错误。以下图为例:

图a中,很容易从整个图像信息看出人在洗车,但是两阶段方法很难预测,因为它们通常只是用bbox内区域,但实际上人box旁边的水管也是关键信息(线索)。就算联合区域的特征可能包括这样的线索,但这些区域也可能被干扰。比如图b,就是HOI实例的重叠,这样的话基于CNN的特征提取器就被迫捕获了两个实例的特征,导致特征被污染。
单阶段方法试图在提取特征、集成特征的早期阶段配对人/物对来捕获上下文信息,而不是单独处理目标。为了确定提取特征的区域,这些方法依赖于启发式设计下的location of interest,比如人-物中心中点。但是这样有时也有问题。如图c,人和风筝离得很远,中点定位在中间无关的人,很难根据中点周围特征来检测。图d则显示多个HOI实例pairs的中点彼此接近。这样CNN就跟图b的问题一样,会有错误的检测。
为了解决这些缺点,作者提出了QPIC,一个基于query的HOI检测器,使用全图上下文信息用一种成对的方式检测人/物。QPIC将一个transformer作为关键组件。QPIC里的注意力机制扫描全图区域,然后根据图像内容选择性地继承上下文关键信息。此外,作者设计了QPIC的queries,使得每个query最多捕获一个h/o对。这就使得,即使HOI实例们离得很近,也可以不污染地单独提取特征。这种注意力机制和基于query的设计让QPIC鲁棒性很高,即使:出现上图a中上下文信息在bbox外的情况;图c目标人/物离得很远;图b多实例离得很近。这样的关键设计产出了有效的embeddings,让后续检测头更简单直观。
总的来说,作者有三个贡献:1.提出了基于query的QPIC,第一个把注意力机制和query方法用到HOI检测的;2.更先进(在当时);3.揭示了传统方法做不到的但是QPIC能做的更好的。
相关工作
先是说,两阶段方法先用Faster RCNN等定位目标,然后从定位到的区域提取特征,送到multi-stream networks。然后每个stream处理得到的目标人、物以及一些辅助特征(比如人体姿势等)。一些两阶段方法也用图神经网络来细化特征。这些方法主要聚焦于第二阶段的架构,也就是用提出来的特征去预测动作。这种方法会丧失全局信息。
最近呢提出了一阶段方法,利用一个人/物对的集成特征。CenterNet用中点收集到的特征来预测动作。PPDM实现了同时目标检测和交互检测的训练,与本文作者训练方法最相似。不过这些方法都收到CNN局部性影响,有时特征还会被污染。
然后作者直接说,他们利用DETR作为基本检测器并扩展到HOI任务。
方法论
为了全图范围内有效对于每个HOI实例提取关键特征,作者利用基于transformer的架构作为一个基本的特征提取器。整体架构如图所示:
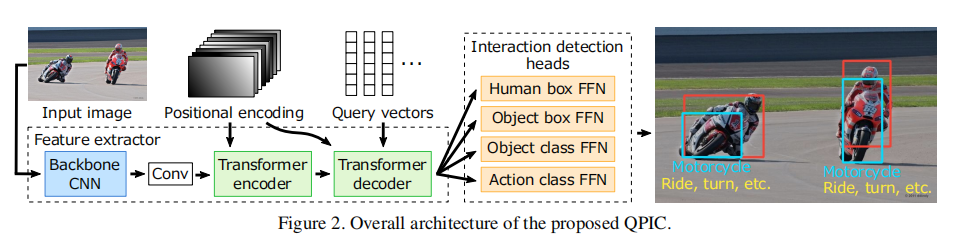
架构总览
上图展示了QPIC总体架构。给定一个图像x(3*H*W),可以由一个任意的现成的主干网络得到特征图
之后,transformer编码器把这个特征图(记作
transformer的解码器把一组可学习的query向量
后续的交互检测头进一步处理解码的embeddings,产生Nq个预测结果。这里,一个人/物对对应的一或多个HOI被数学定义为下面四个向量:一个根据相应图像大小归一化的人框
对于预测的值(就是b,c,a加了个),两个bbox是最后分别接了一个sigmoid出来的,物品接了一个softmax,而动作接的是个sigmoid。注意,
损失函数
损失函数由两阶段组成:预测和真实值的二分匹配;对于匹配对的损失计算。
对于二分匹配,作者依据DETR的训练过程,利用匈牙利匹配算法。首先,作者把h/o对的真实值集合用φ(表示no
pairs)填充到Nq大小。之后作者利用匈牙利算法决定所有可能的Nq个元素的全排列(记作
s.t.是满足...;
最后,基于匹配对,训练中要最小化的损失如下:
其中四个λ是超参数,调整每个损失的权重;
交互检测推理
如前所述,一个HOI检测结果是个<hb,ob,ocls,acls>四元组形式上,我们把对应第i个query和第j个动作的预测结果记为$<{}{()},_{}{()},{k}{}(k),j>
实验
读者自己看吧。作者使用COCO数据集训练的DETR参数来初始化网络;实验在HICO和vcoco上训练,对于v-coco作者排除了v-coco测试集中包含的coco训练图。

