
朴素实现的人-物交互(HOI)检测-论文阅读
论文地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Gupta_No-Frills_Human-Object_Interaction_Detection_Factorization_Layout_Encodings_and_Training_Techniques_ICCV_2019_paper.pdf。
摘要
对于HOI检测任务,本文展示出一个相对简单的因子分解模型,它包含从预训练的目标检测器中构建出的外观(appearance,视觉外观特征)和布局编码(lay-out encodings,用于表示布局信息的编码,可以用来描述目标在图像中的位置、排列、相对关系等),能够胜过更复杂的方法。本文的模型包括了一些因素,用于检测得分、人-物外观、粗粒度(coarse)布局(即box-pair configuration,两个物体边界框对)和可选的细粒度(fine-grained)布局(即一些human pose)。本文也提出了一些训练技巧来提高训练效率:①.消除训练-推理的错误匹配;②.拒绝在小批量训练中出现的易分负样本(easy negatives,即容易正确地分类的负样本);③.使用负样本对于正样本的比例,该比例比现有方法大两个数量级。 本文执行了一个详实的消融实验(ablation study,指切除复杂神经网络中某些部分,来更好地了解网络行为),来了解在HICO数据集上不同因素和训练方法的重要性。
简介
人-物交互(HOI)检测是一个定位一个预定集合中所有人-物交互的实例的任务。比如,检测“人划船”的HOI,就是定位人、船,以及预测人和船之间的“划”这一交互。需要注意,一个图像可能包含多个人划多个船(或同一艘);人也可能同时有许多交互(比如划船、坐在船上、背着包等等)。
相较于复杂的端到端模型,本文提出一种用于HOI检测的简明(no frills)模型,作者使用预训练的object detector提取外观特征,并使用手工制作的边界框坐标特征(可选择使用人体姿势关键点,应该是用到了openpose)编码布局。作者提出的网络架构很简单,仅由轻量级的MLPs(多层感知器)组成,来处理这些提取的外观和布局特征。尽管听起来简化了不少,但是在HICO-Det数据集性能很好。
作者的成果得益于他们因子分解的选择,直接编码和布局评分(choice of factorization, direct encoding and scoring of layout),以及改进过的训练技巧。作者的模型包括人/物检测项(term,术语?)和一个交互项(interaction term)。交互项进一步包括人与物的外观、边界框配置、姿势或精细的布局因素。作者进行了深入的消融实验来评估每个因素的影响。
不同于现有方法训练CNN或混合密度网络来编码布局,作者使用从边界框或人体姿势关键点计算得出的绝对或相对位置特征。他们的选择基于下图的观测(observation):预训练的物体和姿势检测器为交互预测提供了强大的几何线索(作者用的是faster rcnn和openpose)。

从上图看出,作者使用faster rcnn和openpose的预测结果来编码外观和布局,并使用一个因子分解模型来检测交互。
接着,作者给出了一些改进的训练技术。这些是比较重要的部分,很多论文得出的实验指标很高很大程度是因为训练技术很好。
1.消除训练-推断不匹配(Eliminating train-inference mismatch.)之前的方法通过单拎出来的检测loss与交互loss来学习检测项和交互项。在推断时,所有因子的分数简单相乘,来获得最终的HOI类别概率。相反,作者使用一个多标签的HOI分类损失( a multi-label HOI classification loss)来直接优化HOI类别概率。如下面的图2所示。
2.使用指示项拒绝易分负样本(Rejecting easy negatives using indicator terms)。拒绝易分负样本在训练和测试期间是有益处的,因为他可以让模型更专注于学习评分难分负样本。作者使用一个预训练的目标检测器生成一个候选的box-pair(b1,b2),然后由因子模型(factor model)评分。如果b1不是一个human分类或b2不是一个object分类,那么因子模型就给这个(b1,b2)对任何interaction都预测一个0的概率。这是通过在物体检测项中包含一个指示项实现的,并且可以通过在由物体检测器预测的标签上构建出的预测概率上应用掩码(mask)来高效实现,如下图2所示。
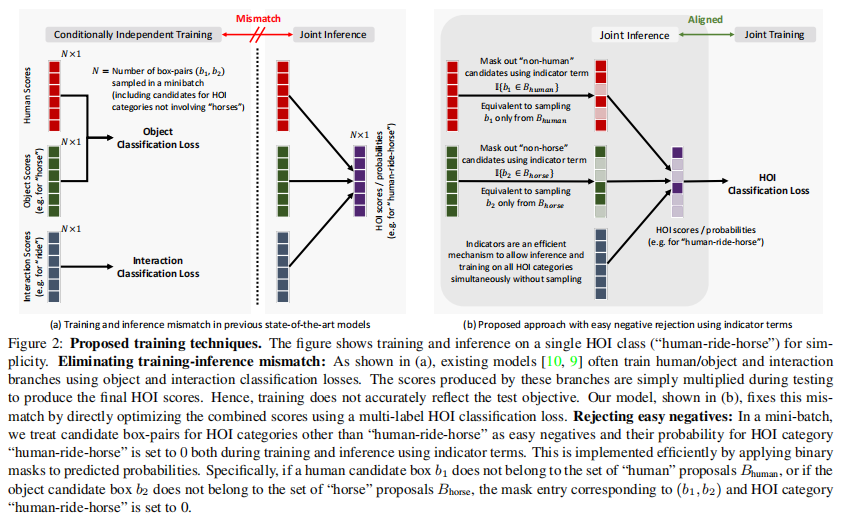
上图是图2.图a显示的是现有模型简单相乘产生HOI分数;图b是作者直接用多标签HOI分类loss来优化结合的分数,消除了不匹配。对于拒绝简单负样本,比如说“人骑马”以外的候选框对看作易分负样本,则在训练和推断时用指示器项将它们类别概率设为0,这是通过将二进制掩码应用于预测概率实现的。
3.使用大的负样本对正样本的比率来训练(Training with large negative to positive ratio.)。作者比起相关工作,在每个正样本对应的负样本框对中,采样了大两个数量级的负样本框对,来构建训练的mini-batch。与物体检测器训练相比,作者期望使用更高的比率,是因为负样本对的数量是物体候选区域(proposal)数量的平方,而相反对于物体检测器而言是线性的。(负比正为10:13.40mAP,而1000时:16.96mAP)。
相关工作
略
No-Frills HOI Detection
作者展示他们提出的模型的总览,随后详细描述了不同的因子和训练策略。
1.Overview
给定一个图片x和一组物体-交互(object-interaction)类别,HOI检测任务就是定位所有包含给出interaction的人/物对。由于需要在人/物边界框的位置和尺寸、物体标签、交互标签上联合搜索,所以训练和推断很有挑战性。为了处理这种复杂性,作者把推理分解为两个阶段,见下面算法。

在第一个阶段,作者使用一个预训练的目标检测器(如Faster
RCN,使用NMS以及分类概率阈值化)来选择物体类别的特定边界框候选集合
在第二个阶段,作者使用一个因子分解模型,对每个HOI类别的人/物框对(
2.Factored Model
对于一个图像x,给定一个人/物候选框对(b1,b2),以及b1内人体姿势关键点k(b1)、每个物体类别的候选框集合,因子分解模型计算这个框对(b1,b2)中出现人/物交互(h,o,i)的概率,如下的(1)式:
2.1 Detector Terms
上面的方程(1)里,前两项是由候选边界框集合,以及一个预训练目标检测器得到的分类概率建模的。对任意物体类别o∈O(包括h),这个检测项(detector
term)会通过下式计算:
项表示将对象类别o分配给图像x中区域b的概率。indicator
function则检查b是否属于
2.2 Interaction Term
交互项表示b1、b2中的实体参与交互i∈I的概率。为了利用外观和布局信息,交互项
Appearance。
