
人-物交互检测(四):GEN-VLKT
与CDN作者是一样的,他们继续改进了工作。论文地址:[2203.13954] GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection (arxiv.org),还有一篇解析文章:CVPR 2022 | GEN-VLKT:基于预训练知识迁移的HOI检测方法-阿里云开发者社区 (aliyun.com),代码仓库:YueLiao/gen-vlkt: Code for our CVPR 2022 Paper "GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection" (github.com)。也是在这一篇文章,引入了CLIP对于HOI的作用。
摘要
HOI检测任务可以被分为两部分:关联人/物和理解交互。这篇论文里,作者从两方面展示并解决了传统query-driven的HOI检测器的缺点。①对于关联人物,先前的两分支方法需要复杂费力的后匹配,单分支方法无视了不同任务的特征差异。作者提出了一个Guided=Embedding Network,叫GEN,来实现一个不需要后匹配的两分支pipeline。在GEN里,作者利用两组独立的query集合设计了一个实例解码器,以及一个position guided embedding(叫做p-GE)来标记同一地方的人和物为一对。此外,作者设计了一个交互解码器来分类交互,它用的是由instance guided embeddings(i-GE)引导组成的interaction queries,这些i-GE是由每个实例解码器层输出的。②对于理解交互,先前的方法会面临长尾分布和zero-shot的问题。本文提出了visual-linguistic knowledge transfer(VLKT)训练策略,通过迁移来自预训练视觉语言模型CLIP的知识增强交互理解。具体来说,作者用CLIP提取了所有labels的text embeddings,来初始化分类器并且采用一个mimic loss来最小化GEN和CLIP之间的视觉特征差异。
简介
作者先从上述两方面回顾了传统方法。
对于关联问题,有两种范式,自顶向下和自底向上。自底向上方法先检测人和物再关联起他们;自顶向下先设计一个anchor表示交互,比如interaction point和queries,然后找到相应的人物对。由于ViT的发展,基于query的方法性能一直领先,它也分为两种:两分支的先预测再匹配方法,和单分支的直接预测方法(HOTR和QPIC)。双分支需要预测交互然后匹配人和物,需要复杂的后处理。单分支以端到端的方式基于单一query检测人、物、交互,但是这三种利用的特征表示是有差距的。前两者主要看重相应区域的特征,交互理解更看重人体姿态或上下文。
为了改善这些,作者提出了一个保有两分支的架构,但是移除了复杂的后匹配,如图a:
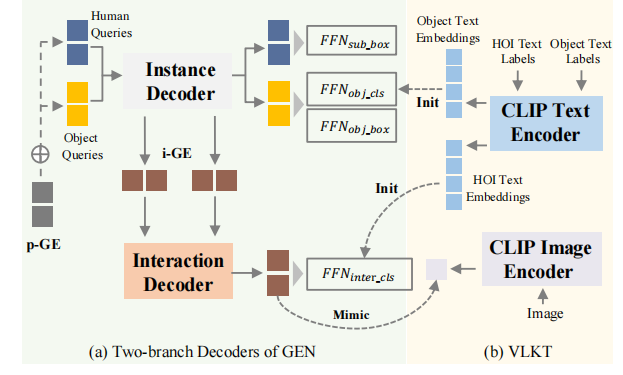
为此,作者提出了GEN,采用一个视觉编码器跟着两分支解码器的架构,也就是实例解码器和交互解码器,并且设计了一个引导嵌入机制来预先引导人物关联。两个分支都有一个基于query的tf解码器架构。对于实例解码器,作者设计了两个独立的query集合用于人/物检测。进一步,作者开发了一个p-GE来区分不同人物对,通过把同人query和物query分配到同一位置上作为一对。对于交互解码器,作者设计了i-GE,由具体的人/物queries引导生成每个交互query,来预测HOIs。因此,GEN可以使得不同任务用不同特征,并且不用后匹配就能引导出人-物关联。
对于交互理解问题,大多数传统方法直接用了个从数据集拟合的多标签分类器,但是这种方法受到因为现实世界复杂活动而造成的长尾分布和zero-shot discovery影响。尽管有些方法利用数据增强和仔细设计的loss来缓解这种问题,性能还是因为广泛的HOI标注导致的有限训练规模影响。于是作者觉得可以放眼image-text数据,来自极其广泛的互联网,可以自然的把HOI三元组变成文本描述。说白了就是得益于CLIP,可以覆盖真实世界大部分HOI场景,带来了理解HOI的新思想。
于是为了改善这一问题,如上图b,作者设计了一个视觉-语言知识迁移(VLKT)训练策略,把CLIP的知识迁移到HOI检测去。在VLKT作者考虑了两个主要问题。一方面,作者设计了针对先验知识集成的文本驱动分类器和zero-shot HOI discovery。具体来说,作者首先转换每个HOI三元组标签到一个词组描述,然后基于CLIP的文本编码器提取text embeddings。最后,用所有HOI标签的text embeddings去初始化分类器权重。这样一来,就可以轻松只通过添加text embeddings到矩阵(?),扩展新的HOI类别。同时,作者也采用了CLIP初始化的物体分类器。另一方面,为了对齐文本驱动分类器和视觉特征,作者提出了一种知识蒸馏方法,来引导HOI检测的视觉特征来模拟CLIP特征。因此,基于VLKT,作者的模型可以捕获CLIP的信息,并且扩展到新的HOI类别,而不需要推理时额外成本。
最后,作者提出了一个统一的HOI检测框架GEN-VLKT。
相关工作
废话就不看了,由于作者也是CDN的作者,他就比较了GEN和CDN的三方面不同:1.解码器组织不同。GEN有一个两分支pipeline和前向实例、交互解码器一起,而CDN解耦了HOI任务到两个解码器,用一个序列方式。2.实例query设计不同。GEN采用独立的human和object query,CDN是把两种耦合成了一个query。3.动机不一样,GEN是为了用引导学习的方式取代复杂的后处理,CDN目的是为了挖掘一/两阶段检测器的好处。
Zero-shot HOI检测就是检测训练集里没有的HOI三元组类别。许多方法用的一种组合学习的方法,就不说了。然后就是CLIP,也不说了。
方法论
总体架构见最上面的图,这一节作者分开讲他们的GEN和VLKT。
Guided Embedding Network
这一小节作者介绍他们的引导嵌入网络,GEN的架构。架构如下图所示:
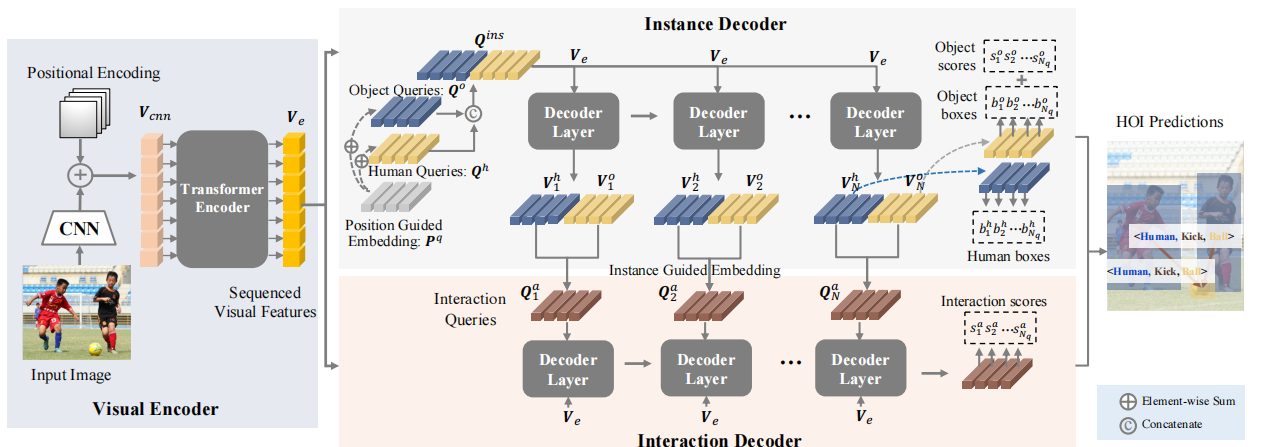
GEN由一个编码器和两个跟着的解码器组成。首先作者用一个配有tf编码器的CNN架构作为视觉编码器,来提取序列视觉特征

