Bellman
Equation(贝尔曼方程)也称动态规划方程,是强化学习的基础和核心,是用来简化强化学习或者MDP问题的。需要知道,贝尔曼方程是用来评价策略好坏的,所以我们可以在后面看到这个方程和策略的关系紧密。
引入
我们先前说过,评价policy好坏的重要标准是return(添加了discount
rate后)。现在我们有如下三种策略:
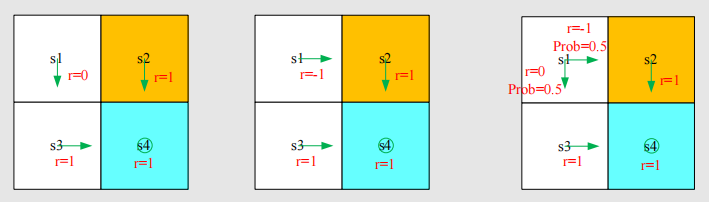
我们依次计算return来评价它们好坏,假设衰减因子是.
policy 1: policy 2: policy 3:
这里的return严格来说已经不是我们基本概念的return了,因为基本概念的return是针对于一个trajectory而言的。我们这里算的其实是一个期望(expectation),也就是我们后面要说的state
value。
计算出三个return后,显然1>3>2。因此第一个策略是最好的。那么如何计算return呢?刚才我们计算return是用的最本质的定义,现在我们换个例子如下:
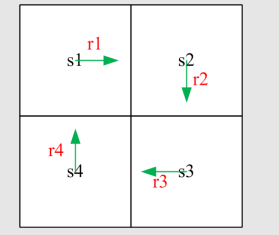
首先我们定义:是当从状态开始时,获得的return值。因此我们有如下等式:
我们观察.
我们提取出,就可以得到: 是不是有点动态规划的感觉?同理我们可以得到:
这组式子告诉我们,不同状态出发得到的return依赖于别的状态出发得到的return,这样的想法在RL中就被成为Bootstrapping,就是从自己出发解决自己。直观上这是不可能的,我们不妨写成更数学一点的矩阵形式:
可以写成如下: 这个我们是知道的,我们也是知道的,它其实是对应state
transition的一些东西。这个就是一个简单的贝尔曼公式,但它真的只是一个简单的,针对于deterministic
case的贝尔曼公式,后面我们会介绍更正式的贝尔曼公式。
这个公式告诉我们,我们的状态的value依赖于别的状态的value(后面会定义),且矩阵形式可以帮助我们求解。这个例子的解就是
State value:状态价值
为介绍state value,我们先考虑一个单步过程: 它包含以下元素:
· : 当前时刻和下一时刻
· : 在t时刻所处状态
· : 在 状态采取的行为
· : 采取后获得的reward ,
有的地方可能写成
· : 采取后迁移到的状态
这里的都是随机值。这些都是由一些概率分布决定的:
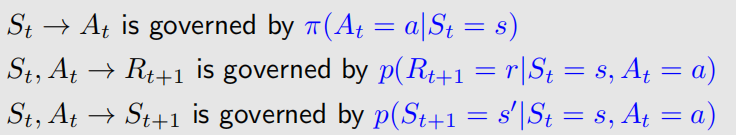
现在考虑一个多步的trajectory: 我们计算出discounted return为: 其中是衰减系数。是随机变量,是因为都是随机变量。现在我们知道了,是对一个trajectory的discounted
return,那么state value就是的期望值(state value全称叫state value
function,即状态价值函数)。我们用如下公式定义state
value: 这是一个关于的函数,并且基于策略。对于不同的policy,state
value可能会不一样。state
value越大,说明处在这个状态可能会带来更大的收益。
return和state value有什么区别?return
是对单个trajectory求值,而state
value是多个trajectory算出来结果的平均。当然,如果只有一个trajectory,那么二者相同。
Derivation:贝尔曼公式的推导
首先根据前面对于的定义,我们可以得到如下公式: 由此,根据期望的线性关系,我们把状态价值函数可以写成:
于是我们的任务就变成了分别求出两个子期望。下面给出推导.首先我们先画个示意图:
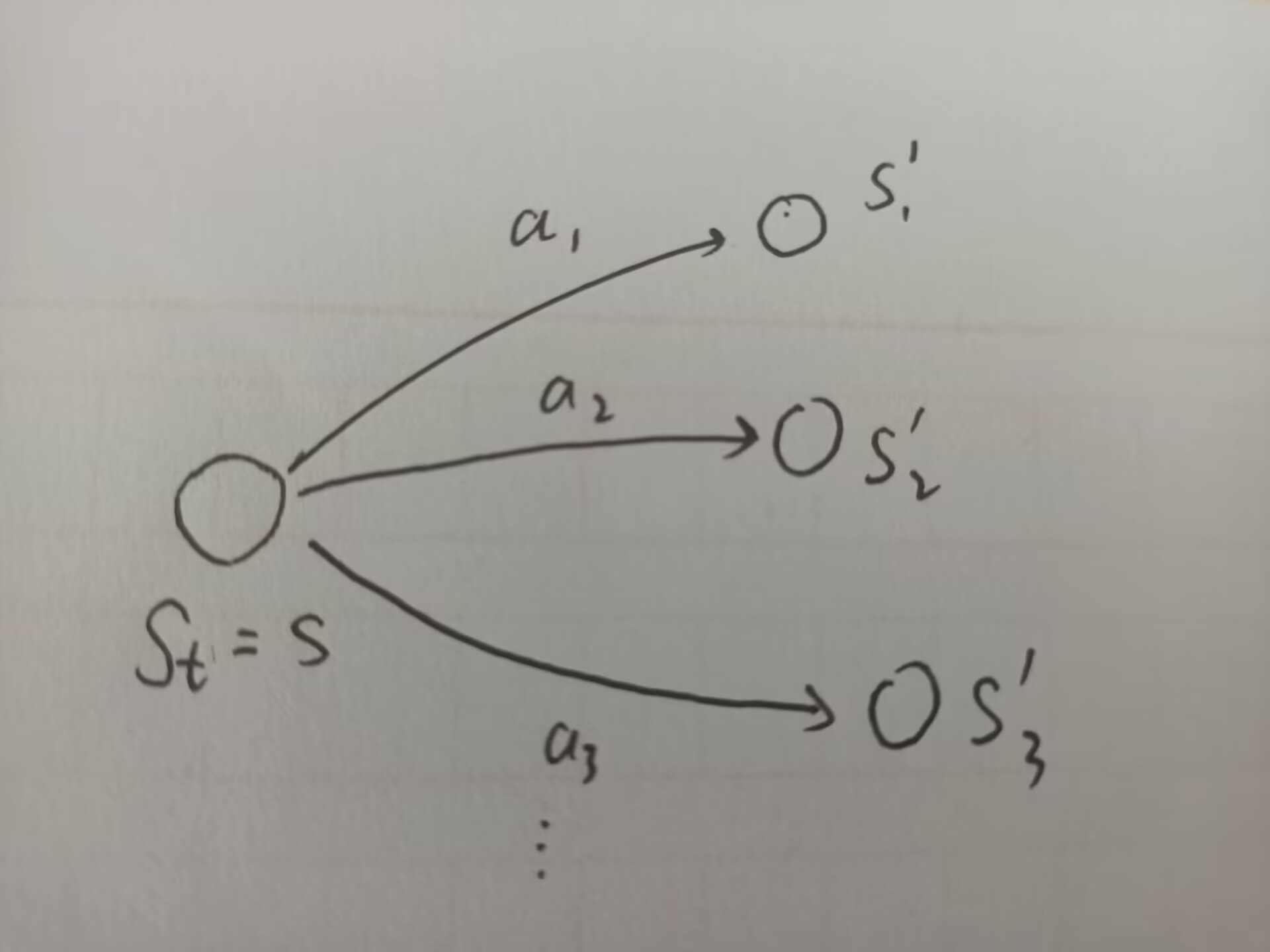
①: :
这个相对来说简单一点,我们要求当前时刻的奖励,就是对采取不同行动时获得的奖励进行一个平均(也就是期望,离散情景下期望公式就是)。而我们采取何种行动取决于我们的策略,因此先对策略求平均:
这个式子后面的 是我们具体的采取行动时,获得的奖励,它是对reward
probability,也就是
的一个期望计算: 于是我们得到最终的结果为: ②.
这个公式是在计算未来获得的return的期望。在我们的示意图中,他就表示为在
时获得的各期望的一个加权平均。显然,直觉上来看,这类似于动态规划,最后的结果会包含 的state value:.
因此先有如下推导: 这里注意变成了,由于马尔科夫性质,我们要计算的东西跟已经无关了。具体来说,这里其实省略了一步:
这里尤其需要注意的是:这里乘的条件概率是而非公式①里用的.
这里一定要区分清楚:在公式①中,我们算的是当前状态出发获得的reward,而reward是只依据当前状态和采取的行动的,是跟策略有关而跟之后到达什么状态无关的(因为我们还有state
transition
probability,并不是采取了一个行动就一定到达一个固定的状态);而在公式②中,我们要计算从当前状态转移到另一个状态的条件概率,它不仅依赖于策略,还依赖于state
transition probability!因此,这里写作;我们可能采取多个行动使得从达到,策略使我们决定采取什么行动,state
transition probability决定我们到哪,那么它的值就是: 由此以来,最终的公式②推导便是:
现在我们得到了两部分的公式,还记得我们最初的公式吗?合并起来就是: 注意这里合并的时候对②的求和进行了一个变形: 这里把第二个后面的看成g(s',a),然后利用了两个求和的性质:
1.与求和量无关的数可以提取出去(自然也可以放到求和里面)
2.有限次的无关的多重求和可以对换次序();无限次的求和要保证级数一致收敛。
至此,我们得到了贝尔曼方程的一般形式:
之后我们会提及它的向量形式写法。求解这个方程叫做policy
evaluation。和代表动态模型,如果未知的话就不能用贝尔曼方程了。下面举个简单的例子来求解。
简单的求解举例
我们的例图如下:
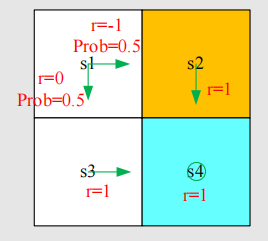
图中有四个状态,我们要列出四个状态的方程。这个例子中,状态1的reward和state
transition都是deterministic的。我们列出四个方程: 可以先求出,然后轻松求出别的值。给定为0.9,可以算出s1~s4的state
value为10,10,10,8.5。
在贝尔曼方程里,我们令: 代入贝尔曼方程,便得到的贝尔曼方程: 我们把所有状态的贝尔曼方程放在一起,就可以得到向量形式:
把它写开,就张这个样子(4个状态为例): 其中叫做state transition
matrix. 就代表了在当前状态采取各行动的奖励期望。我们还是举个简单的例子说明一下,以刚才说过的图例为例:
它的贝尔曼方程的向量形式为:
说完向量形式,该说它的求解了。直观上看,显然贝尔曼方程有闭式解,且解为:
但是在实际中,求矩阵逆是很耗时的,而且通常是在状态数巨大的情况下。因此,我们需要用迭代的思想简化运算。这里就直接给结论了,具体的牵扯到数值计算误差分析的东西,后面就贴一下就行了(就是在证明误差最后趋近于0)。迭代公式为:
可以证明.证明过程为:

Action value:动作价值
state value指的是从一个状态出发得到的return期望,而action
value是指从某一状态采取某一动作后得到的return期望。它的定义为: 显然它依赖于策略。它与state
value有什么关系呢?显然有: 因而有: 我们比较这个式子和之前的贝尔曼公式,可以发现: 这个公式告诉我们,如果我们知道了每一个状态的state
value以及公式中必要的概率,我们就可以知道每一个状态每一个action的value。同样的,state
value公式也告诉我们如果我们知道了每一个action
value,也可以得到每个状态的state value。
这里有个误区就是如果给出的策略中,一个state可以采取的action只有若干,那么其他可能的、潜在的action的value能计算吗?这当然是可以的,实际上我们给出的策略可能是不好的,而action
value就可以用来帮助我们作策略的改进。比如下面的例子:
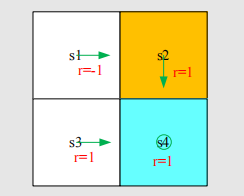
对s1来说,虽然我们的策略只给出了a2这一动作,但是对于其他动作,我们也可以计算出action
value(注意在我们的grid world中,碰到墙壁是弹回本状态):
至此关于贝尔曼方程的基本概念介绍完毕,下节介绍贝尔曼最优方程。

