
周报-20241029
之前.讨论过基站传梯度这样的场景。当时讨论的是联邦学习,其实不是的,那个场景本质还是一个计算卸载,而且有种倒反天罡的感觉:正常来说是边缘节点服务的下游设备将计算任务卸载到边缘节点上。
那什么是联邦学习?通过这些论文的分享也大概了解了,联邦学习是每个设备有一个自己的一小部分数据集,每一轮这些设备自己训练,再汇总到边缘设备聚合。这样的好处是:模型参数由边缘服务器享有,新设备来了也能下载获取;本地设备只需要训练一小部分数据集不用全训,计算效率快而且有泛化性。
对目前见过的模型进行一个汇总:
从计算卸载的角度来看,首先是两层的模型:其中边缘服务器可能是不同区域分开的,也可能彼此有通信。
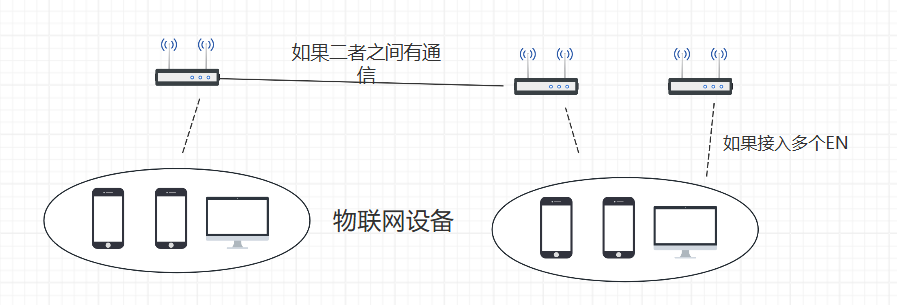
如果考虑接入多个EN,那么决策多了一个应该卸载到哪个EN上。一种情形时:如果IoT本身也要参与计算,那么IoT设备需要决策,这种情况下往往是在这些IoT上都训练了一个RL。这种场景可能往往优化的是总计算时间、能源消耗。
如果考虑不同EN间可以通信,那么决策时要优化的可能就是一个平均时间、负载方差等等。这种情况下,IoT可能就不参与运算了,只是当做它发送任务请求。
一个不同是,这里有些论文的训练方法是FL,而非背景是FL(我觉得)。就是这些论文指出,用FL方式训练的话,即使新接入了IoT设备,也能从边缘服务器上下载模型。如:论文阅读-三篇联邦学习背景下的边缘计算 | 雨白的博客小屋的2和3.
而不同的是联邦学习的背景。
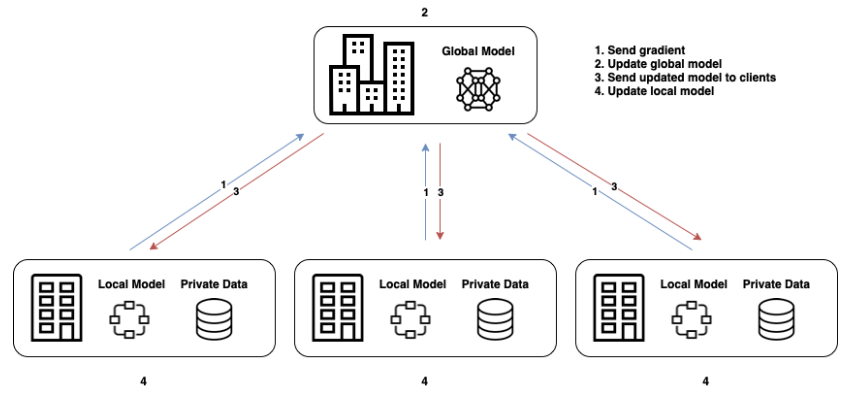 这种场景对应的是上面blog的1和论文阅读-分布式强化学习应用于车联边缘计算中的联邦学习
|
雨白的博客小屋。这是要优化的就可能除了每一轮的训练时间、能耗什么的以外,还有一些由联邦学习带来的模型训练的误差。
这种场景对应的是上面blog的1和论文阅读-分布式强化学习应用于车联边缘计算中的联邦学习
|
雨白的博客小屋。这是要优化的就可能除了每一轮的训练时间、能耗什么的以外,还有一些由联邦学习带来的模型训练的误差。
这种可能最常见的UAV或者车联网。以车联网为例,不同车收集本地观测数据获得本地数据集,分别训练然后传给BS聚合。
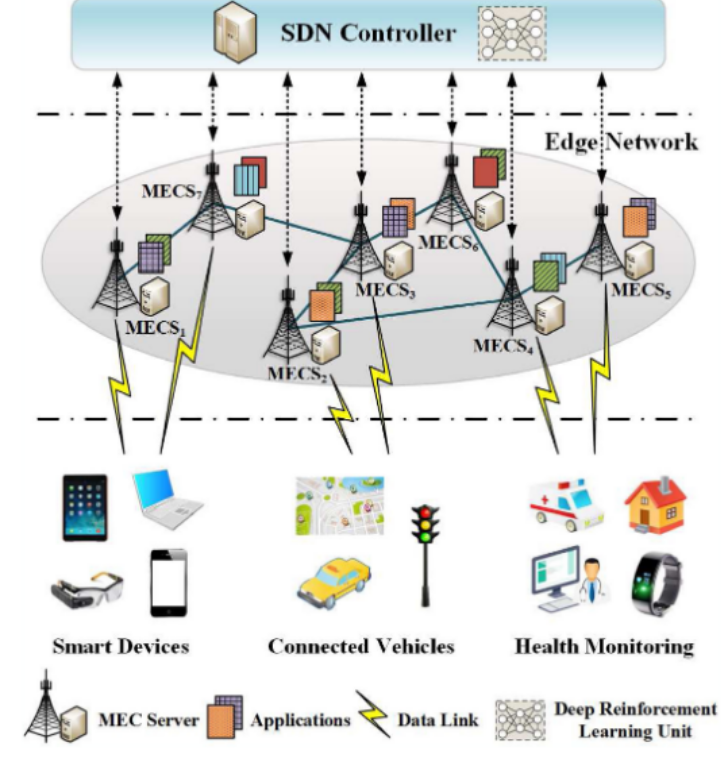
在A comprehensive survey on reinforcement-learning-based computation offloading techniques in Edge Computing Systems - ScienceDirect这篇论文中,阐述了MEC的架构模型:
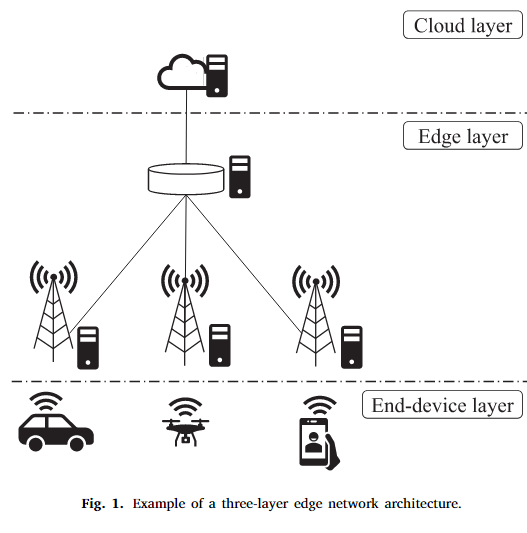
文章提及,MEC包括三层架构,但是大多数文章只会考虑下面两层。不同层之间的距离、传输速率、以及计算能力是不同的,如下:
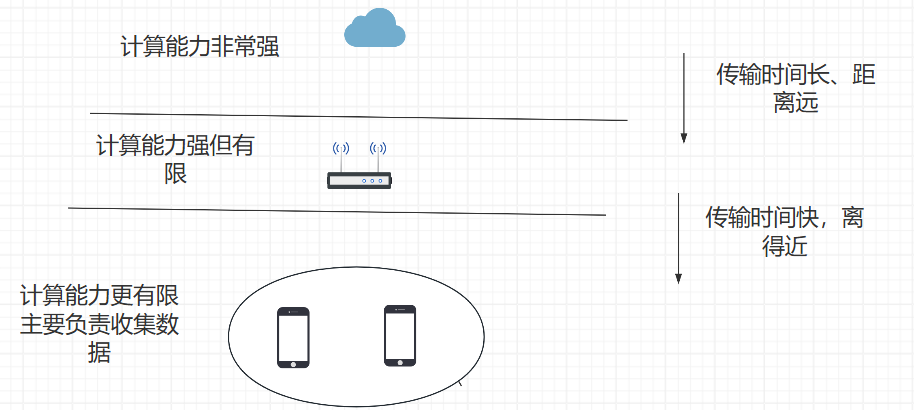
在联邦学习的场景下,可能考虑不到cloud layer,因为传输时间长;在计算卸载的场景下可以考虑,因为有些任务对时间容忍性好,可以慢慢传。
谁决策,谁部署模型。那么,如果IoT设备不用决策,只需要收集数据发给边缘服务器,那就光边缘服务器部署DRL模型。但如果考虑IoT自己也要计算,这种模型就大家全要决策,不确定能不能收敛,好不好训练。(感觉IoT直接传任务的话,应该叫resource allocation而不是task offloading)
要让这个场景更复杂化,就可以像边缘计算与强化学习简述 | 雨白的博客小屋1中讨论的一样,存在多个边缘服务器且彼此之间可以通信。那么边缘服务器可以决策:是本地算,还是给cloud layer,还是给别的服务器。
这么一建模,感觉就像这个了:
其实这个图应该是个二层模型只是统一调度了。
以上是一个场景的初步设想。上次组会也提了一下信道容量分配,那如果边缘服务器要上传到cloud layer的话,就要考虑这个问题了。
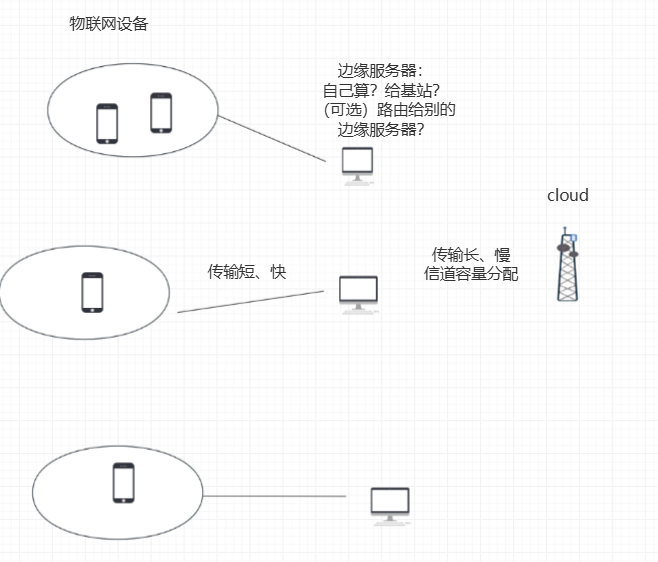
优化的目标的话,这样的场景可能不会考虑能耗了(也可以考虑边缘服务器的能耗)。优化的目标或许就和总的时间有关(计算时间、传输时间等等)。
