
机器学习基础(一):基本概念
前言
本博客主要用来自己学习以及复习考试,由于是课程笔记,所以可能很多东西都是截取的课程PPT。如果您对知识内容有什么看法,欢迎在下方留评论,谢谢~
什么是机器学习
相信对于这个问题,大家在各个博客都已经看烂了。机器学习说白了就是统计学分支出来的,就是基于数据训练出个模型用于新数据。当然,对机器学习没有严格的定义,比如:
“a set of methods that can automatically detect patterns in data, and then use the uncovered patterns to predict future data, or to perform other kinds of decision making under uncertainty.”
反正定义多种多样。简而言之。机器学习是数据驱动的,目标是让机器像人类一样学习、识别、发现、判断。当然,也可以说:机器学习 = training+testing;抑或说,就是寻找一个模型。机器学习的框架如下:
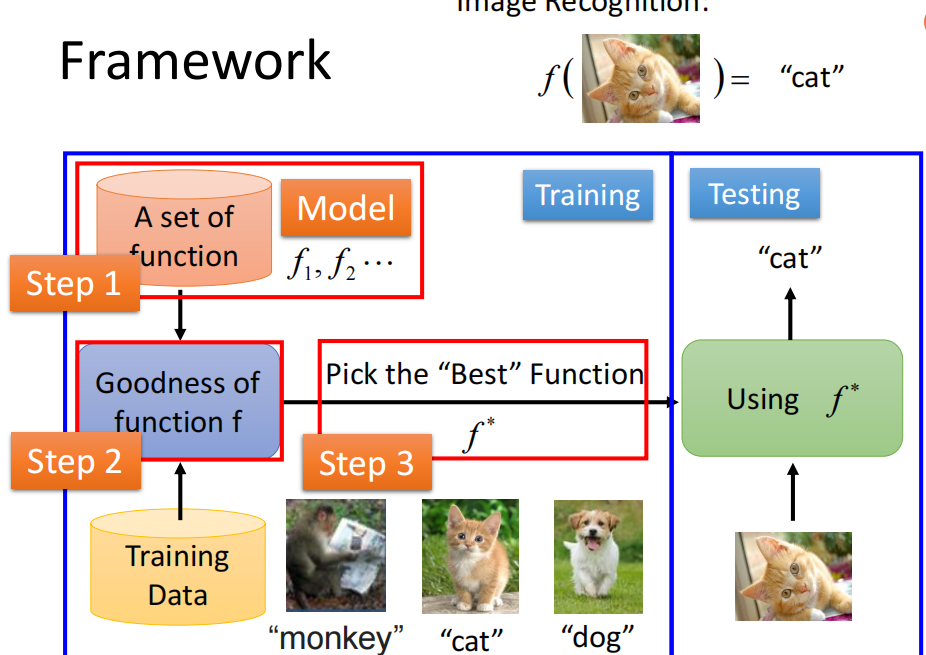
我们以图像识别为例。第一步:我们有一大堆模型,但是我们不知道选哪个。第二步:我们用不同模型训练数据,评价不同模型好坏。 第三步:我们选择表现最好的模型,然后使用它。当然,这只是一个非常、非常普通且宽泛的framework。
之后关注一下机器学习的分类概览:
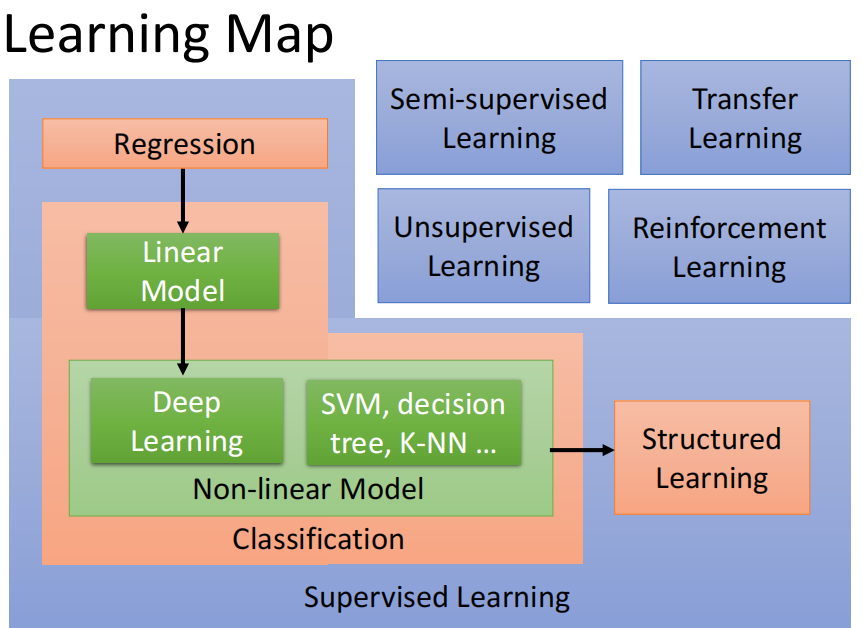
这个图还是有必要记住的。机器学习主要应用场景有:监督学习、非监督学习、半监督学习、强化学习、迁移学习等。图中,蓝色的是应用场景,红色的是任务,绿色的是方法。监督学习和非监督学习的差别就是:是否拥有带有标签的数据。而半监督基于聚类假设,主要应用场景是:我们只有少部分有标签的数据,打标签很费劲,但我们需要大量有标签的数据。
迁移学习有点预训练的意思,就比如你训练一个神经网络,模型的权重可以拿现有权重先初始用着——当然,这需要你用别人的权重不会让你的任务乱套。至于强化学习,只能说天坑,慎入。
总之,我们目前为止重点要关注的是监督学习。监督学习主要包括两大任务:回归和分类。我们之后基本都是围绕这俩东西做文章。回归是对连续值的预测,而分类主要针对于离散值。我们注意到有个structured learning,这主要是针对于语音识别、机器翻译这种任务说的。
基本术语
机器学习中我们会遇到样本、特征、训练集、测试集的等等这种术语。认识这种术语是很有必要的。
模型选择
枯燥的文字太烦人了,还是来点数学能够激动人心。之前我们说过机器学习的framework里需要选出最好的模型,
