
MARL周报(1)
对于城市规划问题,如果把整个城市看作一个单智能体,那么会导致输入输出变得极为复杂,且可能导致过拟合。因此,采用多智能体强化学习(MARL)思想,把每一个城市里的建筑单位看作一个智能体会显著提高效果。如果要实现这样的MARL,就需要一个支撑起其训练的平台,这也是我们项目开始阶段一个重要的问题,那就是搞清楚what to do。当然这肯定不是一个一晚上就能想清楚的问题,是要随着不断探索去细化的。
模糊的说,我们的任务是建立一个platform平台,他们可能有以下关系:

不知道是否可以对比以下深度学习:最底层的是那些诸如numpy之类的库,然后有pytorch,TensorFlow这样的平台。在此之上,我们可以自定义神经网络,自定义算法,然后投入应用。
先参考第一篇老师给的文章:https://www.infoq.cn/article/dleqwrpc-pcek5eq6but。
这篇文章是2018年的了,这时候用的ray版本还是0.6,也就是nmmo用的版本(这时候我记得还没支持windows跑,所以我nmmo都是在虚拟机上跑的)。
第二篇:
开源系列讲座 | MARO群策:多智能体资源调度平台及其基于强化学习的大规模应用_哔哩哔哩_bilibili
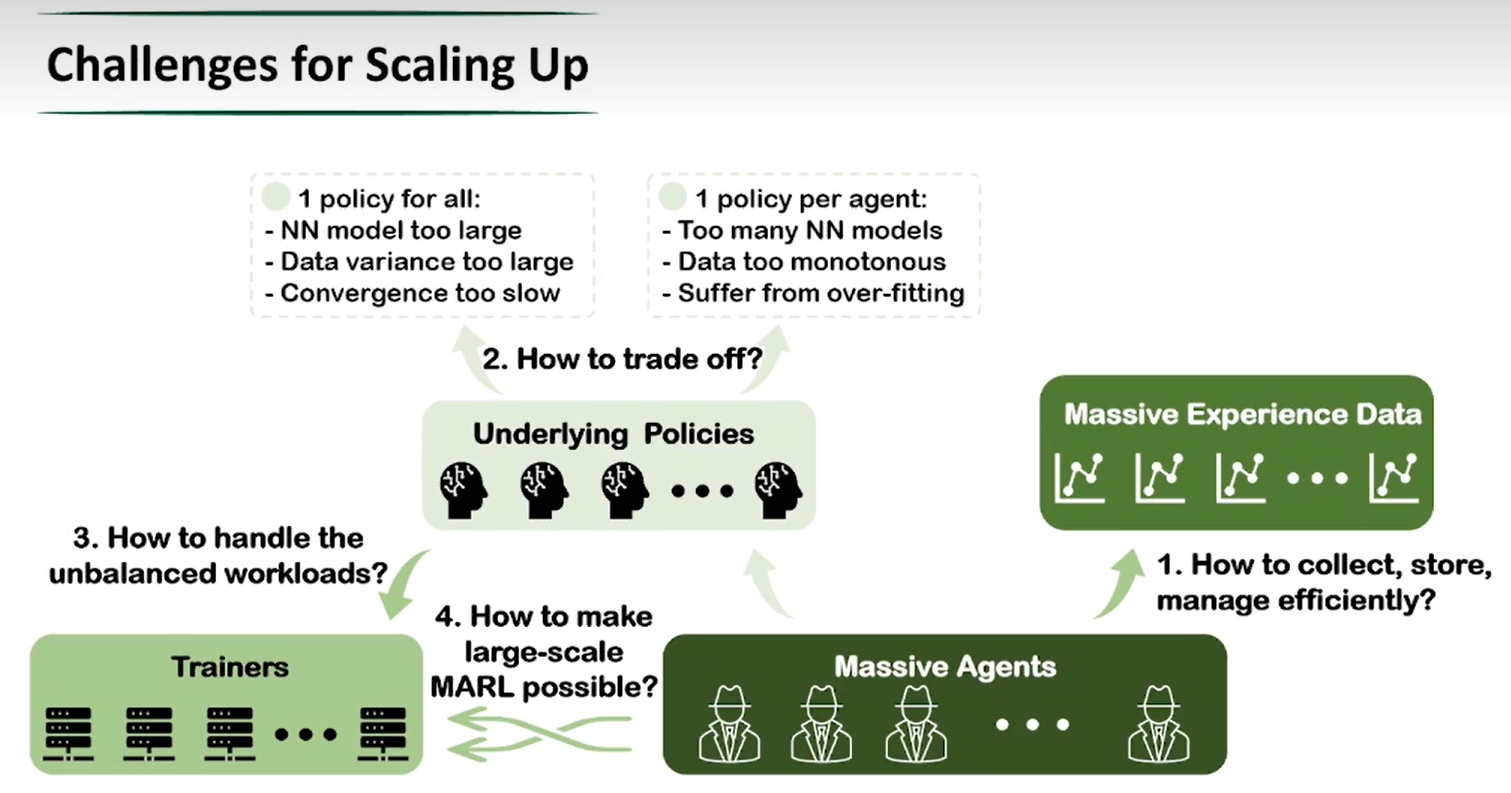
对视频稍微总结了一下,MARL有以下问题:
1.如何存储经验数据?(倾向分配于使用更复杂策略的智能体;分布式大经验池)
2.如何折中:单体策略和群体策略(依据先验知识,相似智能体分配相同策略)
3.如何处理不平衡的工作负载,即训练负载不均衡 (训练资源管理,任务队列)
4.如何实现大规模MARL (视频中没有提及)(跟nmmo的baseline有关?)
结合咱们之前对于NMMO的浅显研究,先看看NMMO提供了什么(我发现NMMO先前官网进不去了,他们换了个最新的官网并且版本更新到了2.0,网址为:Neural MMO - Neural MMO 2.0 documentation):
1.提供一个用于大规模智能体的环境,环境的使用方法为:

这种使用方式与openai gym有相似之处。env.reset()用于初始化环境对象,env.step()用于接受智能体的动作,返回:智能体对当前环境的观测(obs:float)、上一个动作执行完毕后返回的奖励总量、结束标志位、辅助诊断信息(字典类型)。
2.提供配置类型(指定配置)。在NMMO的例子中,可以指定智能体数量、类型、地图路径等等。
3.指定奖励。在NMMO中,用户可以自定义智能体如何获得reward。
4.自定义agent的行为。
以上是对两篇材料结合之前看的nmmo的一个简略的小总结,由于nmmo的官网也翻新了,从1.6升级到了2.0,所以还得重新去官网看看说明和代码。
下一周打算:从一些基本的诸如openai gym库入手,先了解一下基本的关于env,agent等方面的知识和代码形式;学习一些基本算法。
